
Convert paper-basically basically based notes to HTML content with Google Vision API
![]()
We are consistently attentive to diverse recordsdata articles we read since years up to now about how great time we spent in front of our computer programs and how spoiled it’s no longer to non-public a lawful custom about it.
In accordance to a Nielsen Firm viewers file made in February 2018, the average particular person in the United States spent roughly 10 hours and 39 minutes everyday in front of monitors, alongside with the each day employ of smartphones, computer programs, video video games, pills, and TVs.
On the identical time, the skills is ample up to this level to abet us repair this, at the least by diminutive one steps. I was interested in learn how to combine this hassle with this blessing, and I came up with this experiment: writing a weblog article on a paper (What would possibly maybe maybe moreover be without concerns accomplished out of doors), take an image of it and bustle a script to transform it to HTML. The concept that is to employ symbols and letter combos (Equivalent to ‘#T#’) to detect what must be a title, subtitle, represent, or paragraph.
We can originate a program that, given an represent, generates an HTML file. That represent will be a photograph we take, with some marks to parse textual content with some HTML tags. Particularly, we are able to employ this format (Pause with out a doubt be at liberty to write your individual paper to test your handwritten calligraphy, nonetheless you can also positively dispute up the academic using the next represent):

So, as we are able to peruse, we are able to employ #X# symbols to identify a title (#T#), subtitle (#S#), represent (#I#), and paragraph (#P#). For the image, we are able to write the name of the image we are able to employ, without specifying the format -jpg, bmp, png-. In the employ case for the identical outdated particular person, at the time of writing on paper, they’re going to also just no longer non-public the image willing but to dangle, so we are able to employ a placeholder name.
We can employ Node.js with the Google Cloud Vision library to generate the final HTML code (Skip to the underside to stare the academic)
Google’s Vision API wasn’t my first different to be rather appropriate. I wasn’t merely procuring for a instrument to glance textual content internal an represent, nonetheless particular person that acknowledges handwritten words. I desired to establish out Tesseract first since its around for rather some time now and I never had the chance to employ it. Against Google, I only needed to import the Javascript library and employ it, without the gradual activity of making a cloud myth, constructing credentials, and so forth.
But each person is aware of this post is ready Google Vision and no longer Tesseract, so…what came about?

First, I tried with this represent (left), using Tesseract OCR with Node.js. To be appropriate, I was tidy optimistic, so I wrote down about a traces to test the draw it went. I built up a short Node.js utility to read a local represent (Tutorial below on this article), per the up and running tutorial on the Tesseract webpage, transferred the photo to my computer, and examined it.
The wreck end result used to be the next:
At that level, I believed my handwriting used to be ineligible ample to establish out this, so I wrote down a fresh series of traces, taking a diminutive extra of care on the font, and tried again. And I was stunned by an error (In section thanks to memory arrays), maybe thanks to the dimension of the photo (In MB), nonetheless I couldn’t bustle it. Then I started to Google…and I came with Google Cloud Visions API. I built up the up and running tutorial they offer in their attach (All over again, below I will write an academic) with the fresh photo (left)

Most piquant! I wasn’t sure if the difficulty used to be my computer (Since Google analyzer is cloud-basically basically based rather then Tesseract -as far as I know-), or the framework, nonetheless after doing diverse assessments with different form of writings, symbols, numbers, and mixes of capital and non-capital letters I’m able to content that it’s reliable ample to employ.
In present to originate up using Google providers, we need an myth on Google Cloud. Let’s originate https://cloud.google.com/ attach, and click on on ‘Birth without spending a dime’:
Then we are able to be asked to log in with our Google (Gmail) myth, take out our country and procure the terms of carrier. The following step is to arrange our buyer recordsdata, which draw myth form (Substitute or Individual), name and contend with, and the price manner (Credit or debit card). For the time being of writing this article, Google is offering $300 credit without spending a dime for impress fresh customers signing up on Google Cloud Platform for 12 months. Point to that Google makes employ of the credit card to compose sure we’re no longer a robot, nonetheless it indubitably specifies that we received’t be charged until we manually toughen to a paid myth, so the lawful recordsdata is that we received’t win up with a shock invoice from Google.

After signing up, we are able to win a fresh venture:
After establishing the venture, we non-public to suggested the Google Vision API for our venture.
To non-public a shut represent on what Google Cloud affords, let’s the we tap the hamburger menu positioned in the tip-left of the veil veil, and a menu will be displayed listing your entire providers and tools Google Cloud affords. As we scroll down we are able to search out no longer only settings nonetheless moreover providers for computing (e.g. Cloud functions, Kubernetes, VMWare), for storage (e.g. Firestore, SQL, Bigtable, Memorystore), for networking (e.g. VPC network, Network Security), for operations (e.g. Logging and Monitoring), tools adore Cloud Bear, Deployment Supervisor or Cloud Projects, for gargantuan recordsdata (e.g. Pub/Sub, Dataflow, IoT Core), for synthetic intelligence (e.g. AI Platform, Natural Language, Suggestions AI, Vision, Video Intelligence), Google Maps, Game Servers, and partner solutions that capabilities Redis, Apache Kafka, DataStax Astra, Elasticsearch, MongoDB Atlas and extra.
To allow the API for Google Vision, let’s enter right here: https://console.cloud.google.com/apis/api/imaginative and prescient.googleapis.com/overview
After we allow the carrier clicking Enable API, we non-public to enact one extra step in present to employ Google Cloud providers on our computer, which is authenticating. To win this, we are able to win a carrier myth, which is a Google myth that’s associated with the Google Cloud Mission we’re constructing, in desire to a particular particular person.
We can plod to the tip-left menu and peruse the ‘Provider Accounts’ option in IAM & Admin:
Then we click on ‘Compose carrier myth’, and the next create will be displayed. The finest necessary field is ‘Provider myth name’, which is able to without concerns be the name of your venture:
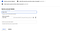
When the carrier myth is created, we return to the listing of carrier accounts (Support in IAM & Admin > Provider Accounts) and we win a key for the credentials:
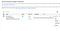
And we download the major as JSON:
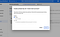
The following step is to add to PATH the non-public key, so the Google Cloud SDK can affiliate it with our myth. In my case, I saved the file in my instrument/credentials folder, so as to reference it we are able to add at the tip of our ~/.bashrc file:
export GOOGLE_APPLICATION_CREDENTIALS="/house/juancurtiit/instrument/credentials/visiontest-XXX-XXX.json"
In my case, I will dispute up the academic on Placing in Google Cloud SDK for Linux, since I’m using a Google Pixelbook machine running chromeOS+Linux. For the remainder of the customers, the instructions are readily obtainable on https://cloud.google.com/sdk/docs/quickstarts.
We can originate the terminal and bustle the next instructions, from gcloud Debian quickstart to set up the SDK:
# Add the Cloud SDK distribution URI as a bundle offer
echo "deb [signed-by=/usr/share/keyrings/cloud.google.gpg] http://programs.cloud.google.com/well suited cloud-sdk predominant" | sudo tee -a /and so forth/well suited/sources.listing.d/google-cloud-sdk.listing# Import the Google Cloud Platform public key
curl https://programs.cloud.google.com/well suited/doc/well suited-key.gpg | sudo well suited-key --keyring /usr/share/keyrings/cloud.google.gpg add -# Change the bundle listing and set up the Cloud SDK
sed -i '1iexport PATH="/usr/lib/google-cloud-sdk/bin:$PATH"' ~/.bashrc
sudo well suited-win replace && sudo well suited-win set up google-cloud-sdk
Now we are able to initialize the SDK, running the shriek gcloud init; this shriek is precious to produce diverse total SDK setup obligations. These obligations consist of authorizing the SDK tools to access Google Cloud Platform using your particular person myth credentials and constructing the default SDK configuration.
So, let’s bustle the init shriek:
gcloud init
We would be asked to log in using your Google particular person myth, which is able to originate our browser to permit us to grant permission to access Google Cloud Platform resources.
To proceed, you non-public to log in. Would you would favor to log in (Y/n)? Y
After authorizing GCP, support in the terminal we are able to be asked to take out the cloud venture to employ until you non-public just one venture:
Seize cloud venture to employ:
[1] [my-project-1]
[2] [my-project-2]
...
Please enter your numeric different:
Now we’re willing to write valid code! Initially, it’s required to non-public Node.js installed:
Let’s win a folder:
mkdir googlevision
cd googlevision/
npm init --yes
Now we non-public to import the Google Vision library
npm set up @google-cloud/imaginative and prescient
Bear the entry level of the node utility:
touch googlevision.js
In the identical folder, add the photo you took of your code (Or download the next photo). My file is is named pic2.jpg
To compose sure we’re going in the excellent form draw, we’ll verify out to win the horrible textual content of this represent. In present to enact this, let’s add the next code in googlevision.js:
const imaginative and prescient = require(‘@google-cloud/imaginative and prescient’);async characteristic app(){
const client = fresh imaginative and prescient.ImageAnnotatorClient();
const fileName = ‘pic2.jpg’;const [result] = predict client.documentTextDetection(fileName);
const fullTextAnnotation = end result.fullTextAnnotation;
console.log(`Consequence: ${fullTextAnnotation.textual content}`);
}app();
When running this, we win the next:
node googlevision.js
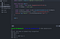
Now we are able to originate up generating the HTML. For this, we are able to win a helper characteristic (convertToHtml).
Let’s replace the console.log line in our app manner for this:
convertToHtml(fullTextAnnotation.textual content);
And we win, below app(), our manner:
characteristic convertToHtml(textual content) {}
Now we would like to justify about a things. Forward of generating the HTML we non-public to clear up the code generated by Google Vision API. Shall we embrace, I added (on cause) the line with
#P# Text 1 #P# Text 2
The diagram used to be with a conception to add extra than one traces writing a clear line on valid paper, in present to construct it apart and no longer extinguish diverse pages for a single post article.
In this case, we non-public to detect each case where internal a line appears to be like bigger than one image. Since we are able to iterate thru the generated textual content line by line, we are able to compose employ of the linebreak (‘n) to separate the parts of the textual content.
Then we are able to need iterate line thru line and changing the emblem for the corresponding HTML code.
We can replace #T# for H1, #S# for H2, #I# for an represent, and #P# for the paragraph. You are going to also add classes, ids, kind tags, JavaScript calls, the whole lot it’s probably you’ll maybe presumably like in present to generate a bigger custom-made and non-public end result.
Then we are able to enact a post-clear, which draw hanging off undesirable spaces ahead of and after opening and closing tags (e.g.: “
” to “
”).
We can need:
- An image called “test”, since that’s what I wrote on paper subsequent to the #I# Image tag. I regarded for a random photo at google for the gaze of the instance, you can also employ regardless of photo it’s probably you’ll maybe presumably like, correct form renaming it to test.extension.
- Now we non-public to set up the fs module in present to win a file. For this, we are able to set up it:
npm set up fs — place
We import it at the tip of our googlevision.js file:
const fs = require(‘fs’);
And we dangle our convertToHtml characteristic with the next:
characteristic convertToHtml(textual content){
//preclean
var cleanText = textual content;
[“#t#”, “#s#”, “#i#”, “#p#”].forEach((merchandise, i) => {
cleanText = cleanText.cleave up(merchandise).be half of(“n”+merchandise.toUpperCase());
cleanText = cleanText.cleave up(merchandise.toUpperCase()).be half of(“n”+merchandise.toUpperCase());
});
cleanText = cleanText.cleave up(“nn”).be half of(“n”);var traces = cleanText.cleave up(“n”);
var resultHTML = “”
var imageFormat = “.jpg”traces.forEach((line, i) => {
var temp = line.substring(3);
if(line.toUpperCase().contains(‘#T#’)) {
resultHTML = resultHTML + “”+temp+”
”
}else if(line.toUpperCase().contains(‘#S#’)) {
resultHTML = resultHTML + “”+temp+”
”
}else if(line.toUpperCase().contains(‘#I#’)) {
resultHTML = resultHTML + “”
}else if(line.toUpperCase().contains(‘#P#’)) {
resultHTML = resultHTML + “”+temp+”
”
}
});
resultHTML = resultHTML + “”//postclean
var tags = [“”, “
”, “
”];
fs.writeFile(“test.html”, resultHTML, characteristic(err) {
tags.forEach((tag, i) => {
resultHTML = resultHTML.cleave up(tag+” “).be half of(tag);
var closingTag = tag.cleave up(“<”).be half of(“ resultHTML = resultHTML.cleave up(“ “+closingTag).be half of(closingTag);
});
resultHTML = resultHTML.cleave up(“src=’ “).be half of(“src=’”);
if(err) {
return console.log(err);
}
console.log(“The file used to be generated!”);
});
}
If we bustle again the script, a test.html file will be generated
node googlevision.js
The wreck end result is the next:

Github: https://github.com/juancurti/tutorial_photo_to_html
Indeed using an OCR library(Optical Character Recognition) combined with creativity can discontinuance up on fabulous results. If we alter the convert manner we are able to no longer only generate static recordsdata nonetheless moreover post it robotically on all platforms, it’s no longer restricted only to originate, nonetheless to the imagination. Absolutely I will enact an academic regarding this soon. In the intervening time, test this on your individual with your individual calligraphy and test if right here’s something you can also compose employ of. You are going to undoubtedly employ fewer hours in front of the veil veil with this.