
How Time Series Databases Work–and The set up They Manufacture no longer
In my outdated submit, we explored why Honeycomb is implemented as a disbursed column store. Merely as gripping to take into legend, although, is why Honeycomb is no longer implemented in varied suggestions. So on this submit, we’re going to dive into the topic of time sequence databases (TSDBs) and why Honeycomb couldn’t be restricted to a TSDB implementation.
For of us that’ve light a feeble metrics dashboard, you’ve light a time sequence database. Even though metrics are cheap to generate, they had been historically rather costly to store. TSDBs are resulting from this fact ubiquitous this expose day because they’re particularly optimized for metrics storage. However, there are some things they aren’t designed to deal with:
- They might be able to’t successfully store excessive-cardinality knowledge.
- Write-time aggregation loses the context of the raw knowledge, making it valuable to answer to unusual questions.
- With out knowledge to uncover pre-aggregated metrics to every varied, your investigations will even be led down the nasty path.
In contrast, our disbursed column store optimizes for storing raw, excessive-cardinality knowledge from which you shall be ready to bag contextual traces. This originate is flexible and performant enough that we can improve metrics and tracing the employ of the identical backend. The identical can’t be said of time sequence databases, although, that are hyper-if truth be told perfect for a explicit form of info.
But it be a need to to know the principles sooner than you shall be ready to interrupt them. So what makes a TSDB tick? Whereas the particulars count on the explicit implementation, we’ll deal with Facebook Gorilla, which has been critically influential. By discovering out the compression algorithms launched by the whitepaper, we’ll be taught about the classic originate of TSDBs. This then informs our dialogue about the true-world considerations with seeking to count on TSDBs for observability.
Metrics, time sequence databases, and Facebook Gorilla
Potentially the most total unit of carrier monitoring is the metric. Metrics are if truth be told appropriate numbers that select some valuable part of info about your ambiance. They’re critically valuable for system-degree diagnostics: CPU utilization percentage, bytes of free memory, substitute of community packets sent, and heaps others. But the premise is so easy that knowledge customarily will get generated for utility-degree insights, too: milliseconds of set apart a query to latency, substitute of error responses, domain-explicit measurements, and so on. (As we’ll behold, vanilla metrics aren’t if truth be told as valuable for this latter form of info.)
Importantly, metrics commerce over time. You might perchance maybe maybe’t appropriate pick one discovering out of your CPU usage and bag a eternal image of your system’s health. As a substitute, you might want to defend taking readings now and again at an everyday sequence interval (e.g., every 15 seconds), recording every metric’s tag alongside with the time when it was measured. Storing this knowledge is the set up time sequence databases worship Prometheus, InfluxDB, and Direct reach into play.
A time sequence is a sequence of info capabilities the set up every point is a pair: a timestamp and a numeric tag. A time sequence database stores a separate time sequence for every metric, allowing you to then seek knowledge from and graph the values over time.
Originally gaze, this doesn’t seem so complex. The TSDB would maybe maybe also store every point in all of 16 bytes: a 64-bit Unix timestamp and a 64-bit double-precision floating point number. As an instance, a time sequence for your CPU stats would maybe look worship this:
| Unix timestamp | CPU usage (%) |
| 1600000000 | 35.69 |
| 1600000015 | 34.44 |
| 1600000030 | 32.19 |
| 1600000044 | 53.94 |
| 1600000060 | 37.56 |
The timestamp is an integer substitute of seconds since the Unix epoch, which naturally increases over time. Here, we can bet there’s a 15-2d sequence interval, even although in the true world there’s stride to be some jitter the set up the clock shall be off pretty here or there. The CPU usage is a floating point number that potentially hovers around the identical tag if the system is healthy, nonetheless would maybe maybe also behold dramatic spikes. Other metrics would maybe maybe even be representable as integers, nonetheless the employ of a floating point kind is more total.
However, this uncomplicated illustration has considerations at scale. No longer handiest are metrics prolific, nonetheless the sheer substitute of services and products producing these metrics in modern disbursed programs formulation that a TSDB shall be declaring hundreds and hundreds of interesting time sequence true now. With out notice, these 16 bytes originate up adding up. Fewer sequence will even be held in memory, so efficiency suffers as writes and queries need to hit the disk. Then long-term storage turns into more costly, so less knowledge will even be retained.
Thus, a main avenue of optimization for TSDBs is compression, reducing the bogus of bits desired to symbolize the identical knowledge. Since time sequence like a extraordinarily explicit structure, we can leverage if truth be told perfect encodings. In explicit, two compression schemes had been launched by Facebook Gorilla that like influenced quite a lot of quite a entire lot of TSDBs, including Prometheus (behold this PromCon 2016 focus on) and InfluxDB (as a minimal version 1.8). Examining these two schemes—one for timestamps, one for values—will give us a total feel for the styles of considerations that TSDBs resolve.
Optimizing time sequence databases
To compress timestamps, the principle direct to ogle is that they’re consistently growing. When we all know the preliminary timestamp, we all know that every subsequent timestamp is offset towards the outdated one. This presents upward push to delta encoding, which stores the diversifications as an substitute of the raw values. As an instance, our CPU time sequence from sooner than has the following deltas for every of its timestamps:
| Unix timestamp | Delta |
| 1600000000 | – |
| 1600000015 | 15 |
| 1600000030 | 15 |
| 1600000044 | 14 |
| 1600000060 | 16 |
We aloof need to store the principle timestamp as a 64-bit integer, nonetheless the deltas are far smaller, so we needn’t employ as many bits.
But we can trip one step further by noticing that the deltas are nearly all of the identical. If truth be told, resulting from the periodic nature of metrics, we set apart a query to the deltas to be equal to the sequence interval (here, 15 seconds). There’s aloof the bogus of jitter, although, so we can’t appropriate buy the deltas are consistently going to be the identical actual tag.
Realizing this, we can compress timestamps even more by making employ of delta encoding to our delta encoding, giving us a delta-of-deltas encoding:
| Unix timestamp | Delta | Delta of deltas |
| 1600000000 | – | – |
| 1600000015 | 15 | – |
| 1600000030 | 15 | 0 |
| 1600000044 | 14 | -1 |
| 1600000060 | 16 | +2 |
After storing all 64 bits of the principle timestamp, then the principle delta for the 2d timestamp, we can appropriate store the delta-of-deltas. Rather then in conditions of jitter, we set apart a query to the delta-of-deltas to be 0, that would maybe maybe also unbiased be kept in a single bit. For Facebook, they learned this to be the case for 96% of their timestamps! And even the variances resulting from jitter are anticipated to be minute, which enables us to achieve an aggressive compression ratio.
A identical strategy will even be light for metric values as neatly. However, we don’t like the identical constraints that enable for easy deltas. In precept, subtracting any two arbitrary floats appropriate finally ends up in one other waft, which takes the identical substitute of bits to encode. As a substitute, we flip to the binary illustration of our double-precision floats, as specified by the IEEE 754 standard.
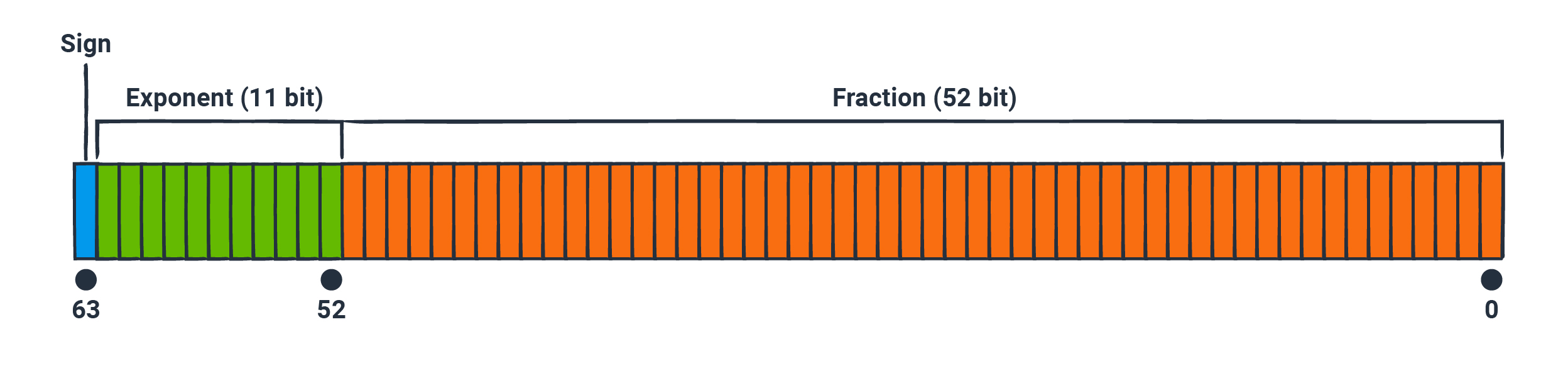
The 64 bits are broken up into three aspects: the signal (1 bit), the exponent (11 bits), and the part (52 bits). The signal bit tells us whether or no longer the number is definite or negative. The exponent and part work nearly the identical formulation scientific notation does in contaminated 10, the set up the number 123.456 would prefer the fractional phase of 0.123456 and the exponent of 3, since 0.123456 × 10^3 = 123.456. You might perchance maybe maybe accept as true with the exponent as an explain of magnitude, while the part is the “payload” of the number.
Within a single time sequence, it’s reasonably seemingly that the values are going to like the identical signal and explain of magnitude, so the principle 12 bits are potentially the identical between measures. As an instance, CPU usage is consistently a definite number between 0 and 100. The fractional values would maybe also finish pretty conclude collectively, nonetheless there’s potentially more fluctuation. As an instance, the CPU usage would maybe cruise around the identical narrow band so long as the system is healthy, nonetheless it surely would maybe maybe also spike up or rupture down.
Thus, as an substitute of subtracting subsequent values as in delta encoding, we can attain a bitwise XOR between successive values. The first 12 bits will customarily be the identical, so their XOR shall be zero. There will even be some substitute of trailing zeroes—more if the binary representations are conclude collectively. The usage of hex notation for the sake of compactness, our instance CPU usage metrics like the following XOR outcomes:
| CPU usage (%) | Hex illustration | XOR with outdated |
| 35.69 |
0x4041d851eb851eb8
|
– |
| 34.44 |
0x40413851eb851eb8
|
0x0000e00000000000
|
| 32.19 |
0x40401851eb851eb8
|
0x0001200000000000
|
| 53.94 |
0x404af851eb851eb8
|
0x000ae00000000000
|
| 37.56 |
0x4042c7ae147ae148
|
0x00083ffffffffff0
|
Why effort with this? Due to in want to store all 64 bits of the XOR result, we can employ its predictable shape to thought a custom encoding. As an instance, take into legend the associated rate 0x000ae00000000000, which in binary consists of 12 main zeroes, 7 valuable bits (1010111), and 45 trailing zeroes. We are going to encode every “chunk” individually:
- As a substitute of writing out the 12 main zeroes as
000000000000, we can write the number 12 as1100the employ of handiest 4 bits. - The a entire lot of bits need to be written out in elephantine, nonetheless the bogus of bits is variable. So we write the bogus of valuable bits adopted by the bits themselves. Here, that’s
111(7) adopted by1010111for a total of 10 bits. - The substitute of trailing zeroes is implied by the guidelines encoded above. We know the elephantine width is 64, and 64 – 12 – 7 = 45. So we needn’t encode the leisure else for the closing chunk.
Thus, as an substitute of 64 bits, we can represent this tag in as few as 4 + 10 + 0 = 14 bits. In apply, this isn’t rather the discontinuance result. We would maybe maybe like additional bits to delimit the chunks, and there are varied tricks to squeeze a pair bits out. However, the final notion is aloof the identical.
As we can behold from the instance, although, this compression diagram has more variability. The first three XOR outcomes like quite a lot of zeroes, so they compress by a lot. The closing result aloof has quite a lot of main zeroes, nonetheless no longer so many trailing zeroes, so it compresses less. In a roundabout diagram, the final compression ratio if truth be told will depend on the particular person values of the metric.
Gentle, by combining the 2 compression algorithms, the Gorilla database light by Facebook noticed knowledge capabilities shrink from 16 bytes to a median of 1.37 bytes! With knowledge that minute, more capabilities can slot in memory, main to sooner seek knowledge from efficiency over longer time ranges. It also formulation more inexpensive long-term retention when the values bag written to disk.
There are varied subject matters to take into legend past compression, equivalent to efficiently the employ of disk I/O when a time sequence will get persisted. But this aloof presents us the crux of what’s being solved by TSDBs: storing quite a lot of homogeneous, timestamped, numeric knowledge capabilities with as minute spoil as that you shall be ready to accept as true with. For of us that can worship a model of more optimization subject matters, take a look at out Fabian Reinartz’s PromCon 2017 focus on, “Storing 16 Bytes at Scale.” For our capabilities, although, this notion presents us a foothold for discussing the employ of TSDBs in the wild.
Tagging vs. excessive cardinality
Now that we can defend computer screen of our knowledge capabilities, let’s take into legend how they’re if truth be told light. Converse we like an e-commerce app written in Python the employ of Flask to again varied API endpoints. A extraordinarily inexpensive utility-degree metric would maybe maybe even be the bogus of errors users behold. The usage of something worship StatsD, we would maybe maybe also diagram up an error handler to increment a metric:
import statsd
stats = statsd.StatsClient()
@app.errorhandler(HTTPException)
def handle_error(e):
stats.incr("errors")
# ...
Under the hood, the StatsD daemon is declaring a counter of how many errors we’ve seen one day of the sequence interval. On the discontinuance of each and each interval, the associated rate is written out to the errors time sequence in the TSDB, then the counter is reset to 0. Thus, the counter is basically a payment of errors per interval. If we behold it trending up, something would maybe maybe even be going nasty.
But what exactly is going nasty? This single counter doesn’t repeat us valuable. It shall be some dire computer virus resulting in HTTP 500 errors, or it’ll even be a broken hyperlink in an e-mail campaign main to elevated HTTP 404 errors, or any substitute of assorted things. In explain to split out this metric, it’s very approved for vendors to offer tags or labels—pieces of key-tag metadata that can even be linked to a time sequence. Whereas vanilla StatsD doesn’t improve tagging, clients worship Prometheus attain. As an instance, we would maybe maybe also connect an HTTP set up label worship so:
from prometheus_client import Counter
errors = Counter("errors", "HTTP exceptions per interval", ["status"])
@app.errorhandler(HTTPException)
def handle_error(e):
errors.labels(e.code).inc()
# ...
Even though Prometheus counters work pretty otherwise from StatsD counters, labels work in fundamentally the identical formulation all over TSDBs that improve them. In a roundabout diagram, the database is going to lastly discontinuance up storing a separate time sequence for every designate tag. So for every that you shall be ready to accept as true with set up code, there shall be a definite time sequence with its possess knowledge capabilities. The errors{set up=500} time sequence will own varied knowledge from the errors{set up=404} sequence, so they’ll even be graphed for my piece and we can behold the respective error rates per set up code. The errors sequence represents the sum of these varied ones.
Why dwell there, although? The HTTP set up code isn’t the handiest direct that differentiates errors. For our hypothetical e-commerce teach, we would maybe tolerate varied error rates for the /checkout API than for the /critiques API. We would maybe maybe also add one other designate for the set apart a query to path with a notion to bag as valuable context as that you shall be ready to accept as true with:
from prometheus_client import Counter
errors = Counter("errors", "HTTP exceptions per interval", ["status", "path"])
@app.errorhandler(HTTPException)
def handle_error(e):
errors.labels(e.code, set apart a query to.path).inc()
# ...
Then the errors{set up=500,path=/checkout} time sequence shall be varied from the errors{set up=500,path=/critiques} sequence. But it surely goes past that: the TSDB might want to store a separate time sequence for every queer aggregate of set up and path, including errors{set up=404,path=/checkout} and errors{set up=404,path=/critiques}. Converse there are 10 that you shall be ready to accept as true with error codes and 20 that you shall be ready to accept as true with API endpoints. Then we would maybe maybe even be storing 10 × 20 = 200 varied time sequence.
This isn’t too immoral yet. There are pretty few that you shall be ready to accept as true with values for the tags we’ve added up to now. That is, they like got low cardinality. However, take into legend a designate that has excessive cardinality (many that you shall be ready to accept as true with values). As an instance, a user ID designate shall be at hand, since error eventualities would maybe handiest apply to explicit users. But the bogus of user IDs would maybe maybe even be very excessive, reckoning on how standard the teach is. Converse there are 1,000,000 users. With appropriate these three labels, the TSDB has to store 10 × 20 × 1,000,000 = 200,000,000 varied time sequence. It will get even more unhealthy with tags of unbounded cardinality, worship HTTP Person-Agent strings, that would maybe maybe also unbiased be the leisure.
TSDBs are appropriate at what they attain, nonetheless excessive cardinality is no longer built into the originate. The nasty designate (or simply having too many tags) leads to a combinatorial explosion of storage requirements. Here’s why vendors will most steadily payment primarily based on designate counts, or even cap definite plans at a restricted substitute of tag combos. With a TSDB, you’re no longer ready to label metrics primarily based on one of the most ideal differentiators. As a substitute, it be a need to to work with incorrect-grained knowledge, the employ of at handiest a handful of low-cardinality tags.
Aggregation vs. raw knowledge
Whereas tags can accomplish a time sequence database store too valuable knowledge, there are also suggestions in which TSDBs won’t store enough knowledge. This has to achieve with how metrics bag generated.
Converse we’ve had efficiency points in the past linked to users with enormous cart sizes—that is, the bogus of things users like at checkout. It will seemingly be inexpensive to trace a metric for this, in case we bound into the identical direct yet again. But we wouldn’t be ready to employ a counter worship sooner than since the cart size isn’t cumulative. Assorted users like varied cart sizes at varied instances, even within a single sequence interval. Converse we like a 30-2d sequence interval and we behold the following checkouts one day of the 1600000000 – 1600000030 interval:
| Timestamp | Cart size |
| 1600000003 | 3 |
| 1600000007 | 14 |
| 1600000010 | 15 |
| 1600000011 | 9 |
| 1600000017 | 26 |
| 1600000017 | 5 |
| 1600000026 | 3 |
These are technically timestamped numbers, nonetheless they all happen at varied instances that are unfold out in an unpredictable distribution (maybe even on the identical time as). For the reason that TSDB depends on the regularity of the time deltas, we need to again except the discontinuance of the sequence interval to write a single number to the time sequence. That is, we need an combination number that somehow represents the totality of the guidelines capabilities. A counter is one form of combination the set up the values are summed. But this doesn’t repeat us how many items a usual user purchases. As a substitute, we’d potentially discover to file the moderate cart size per interval.
To trace such metrics, it’s approved for libraries to offer a histogram characteristic:
@app.route("/checkout")
def checkout():
cart = get_cart()
stats.histogram("cart_size", len(cart))
# ...
Broadly speaking, the client will defend a listing of the cart sizes one day of each and each sequence interval. On the discontinuance of an interval, aggregates bag computed from that list and written to the TSDB, then the list is cleared for the subsequent interval. Each and each combination goes in its possess time sequence. They would maybe maybe also comprise:
cart_size.sum= 75cart_size.count= 7cart_size.avg= 10.71cart_size.median= 9cart_size.p95= 22.7cart_size.min= 3cart_size.max= 26
But no topic which combination we’re computing, the true fact stays that we’re throwing away the real knowledge capabilities at write time. You’ll never be ready to read them abet. As an instance, whilst you would also behold the moderate cart size is 10.71, the guidelines capabilities would maybe maybe also appropriate as neatly were [3, 14, 15, 9, 26, 5, 3] or [10, 8, 8, 13, 13, 13, 10] or [7, 11, 12, 16, 16, 9, 4] or any substitute of assorted possibilities. There are additional aggregates you would also compute as neatly as to the moderate to pick out a gaze at to bag a clearer image, equivalent to the usual-or-backyard deviation. But on the discontinuance of the day, the handiest formulation to bag elephantine resolution is to like the raw knowledge readily readily obtainable, which isn’t amenable to being kept in the TSDB.
This would maybe no longer topic for metrics you understand you want sooner than time. We wanted the moderate, so we’re recording the moderate. But it surely with out a doubt matters when somebody asks a seek knowledge from you didn’t look forward to. Let’s scream we behold the cart size moderate hovering round 10, nonetheless we aloof had an outage connected to enormous carts. How enormous is “enormous”? That is, what’s the moderate size of handiest the carts above 10 items? How many outliers are there with more than 20 items? Is the moderate being dragged down by of us with especially minute carts of handiest 1 or 2 items? And so forth.
None of these questions will even be answered primarily based on the averages we’ve been saving to the database. We threw away the real raw knowledge, so we can’t abet-calculate. The ideal direct to achieve is conjure up a unusual metric for knowledge going forward. This puts us into a reactive sample, continuously on the whim of unknown unknowns. Odds are that nobody is going to like the foresight to look at appropriate the specific combination that can enable us to acknowledge these valuable questions about cart sizes, no longer to mention debug some unusual unusual failure mode when we bag paged in the center of the night.
Correlation vs. observability
Let’s image such a failure misfortune. Converse it’s Dark Friday, the ideal day of the year for our e-commerce teach. By the center of the day, indicators originate up going off. That’s k; it’s why we like the proactive alarms wired as a lot as our errors time sequence. So we bag to troubleshooting and commence up the metrics dashboard.
Obvious enough, the graph is exhibiting an depressed lengthen in HTTP 500 errors on the /checkout API. What shall be causing it? Correctly, we’ve seen efficiency points with cart sizes sooner than. It appears to be like inexpensive that this problematic code would maybe result in errors, so we seek the recommendation of the cart_size.avg time sequence to take a look at.
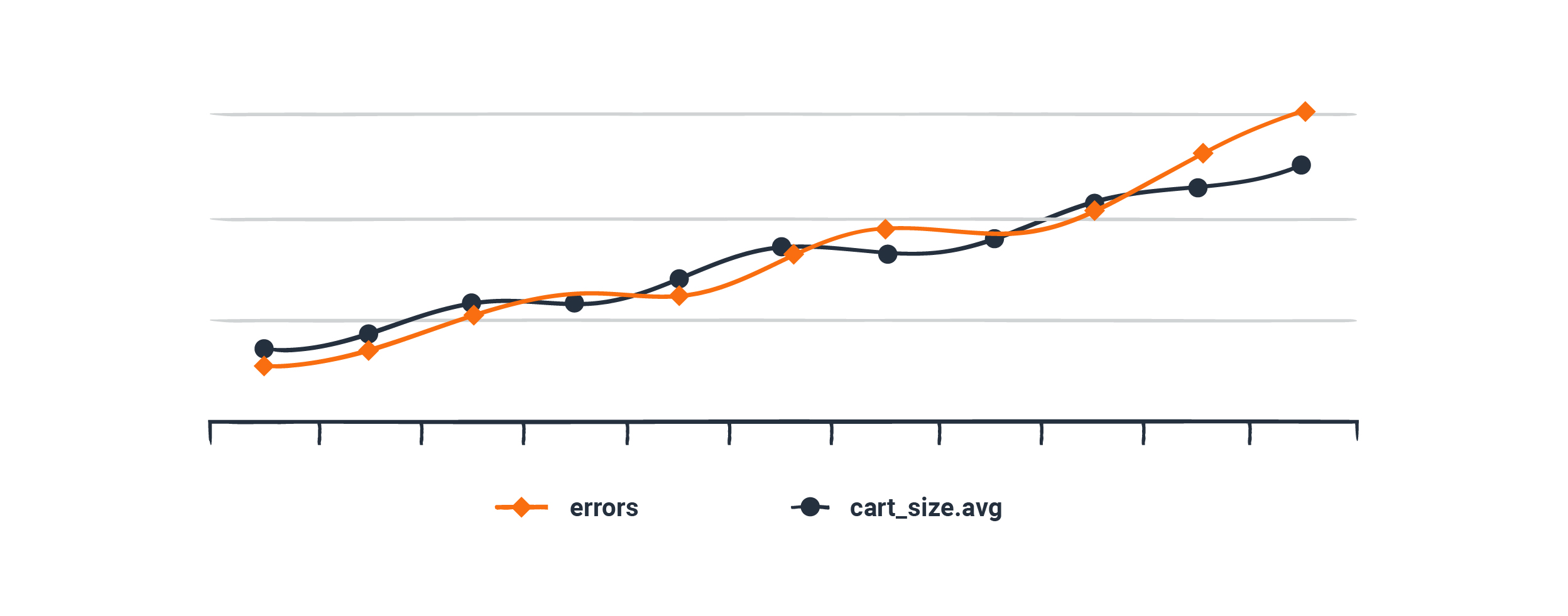
Evaluating it to the errors{set up=500,path=/checkout} sequence, it appears to be like to be worship the cart size and the error rates are rising in lockstep, which appears to be like awfully suspicious. Hypothesis in hand, we diagram out to breed a misfortune the set up a gigantic cart triggers some execute of error.
Rather then this reasoning is unsuitable. We would maybe maybe also spoil an hour digging into this rabbit gap sooner than a buyer improve designate is obtainable in that users can’t apply a explicit coupon code at checkout—an error that has nothing to achieve with the cart size. Cart sizes are appropriate trending up because it’s Dark Friday, and the errors happen to be growing on the identical time resulting from a particular Dark Friday coupon code that is broken.
As they scream, correlation does no longer suggest causation. Humans are elegant appropriate at sample-matching, even when the sample is coincidental. So when we squint on the graphs and take a look at out to line things up, our brains would maybe fetch a fallacious correlation. As an instance, you would also unbiased like heard the one who world warming is triggered by a lack of pirates. In spite of the entirety, as the bogus of pirates has trended down, the moderate world temperature has trended up!
No longer every correlation is a rank one, for optimistic. Yet we aloof possibility chasing these crimson herrings because TSDBs lack the true context—a flaw imposed by their possess originate. We are going to’t designate the errors with the coupon codes that users submit because the cardinality of text enter is form of about unbounded. We also can’t drill down into the aggregates to search out a particular person knowledge point telling us that errors aloof befell at minute cart sizes.
This instance has illustrated an overall lack of observability: the ability to deduce the inner workings of your system by what you behold on the skin. That’s why, in seeking to resolve for observability, Honeycomb couldn’t be restricted to a TSDB implementation.
Honeycomb is varied
Numerous labor has long gone into making time sequence databases very appropriate at what they attain. Metrics are consistently going to be cheap to generate, and with the power of a TSDB, you’ll be ready to with out considerations chart combination traits over long sessions of time. But in phrases of observability, there are loads of suggestions in which numeric time sequence knowledge appropriate won’t select enough context.
Here’s what motivated the originate of Honeycomb’s backend, which optimizes for storing raw knowledge and making queries rapid. So in the areas the set up TSDBs are lacking, the disbursed column store if truth be told shines:
- Storage requirements are no longer depending on the cardinality of your knowledge. Because of the this fact, you shall be ready to connect excessive-cardinality fields to your events at no additional rate.
- Uncooked knowledge is kept at write time, and aggregates are handiest computed at seek knowledge from time. Nothing is thrown away, giving you the ability to chart the incorrect-grained aggregates as neatly as drill down into the gorgeous-grained knowledge capabilities.
- By organizing your knowledge relationally into traces, you no longer need to count on correlating disparate graphs in an strive to glimpse the behavior of your system.
Plus, we can bag metrics from wide events, whereas wide events can’t be derived from metrics. Merely, Honeycomb won’t be as appropriate at compressing particular person time sequence the vogue a TSDB does. But as an substitute, we can bundle collectively all of the metrics on the discontinuance of each and each sequence interval and write them as one row in our column store:
timestamp |
cpu |
mem_used |
mem_free |
net_in |
net_out |
... |
| … | … | … | … | … | … | … |
Due to tracing already presents you so valuable context, you’ll potentially fetch yourself relying less on metrics for utility-degree behavior. Gentle, metrics are valuable for programs-degree diagnostics to designate if your machines are healthy, thought for infrastructure skill, and so on. So it’s price having a backend that helps each and each tracing and metrics.
The point isn’t that TSDBs are rank and column stores are appropriate. As ever, engineering is ready commerce-offs. But now that we’ve seen how TSDBs work, as neatly as how they don’t, we can accomplish our selections with the next notion of what these commerce-offs are. For of us that’d worship to be taught more, take a look at out our docs on Honeycomb Metrics. Delivery up with Honeycomb Metrics with a free Enterprise legend trial!