
The 2021 machine learning, AI, and records panorama

Image Credit: Donald Iain Smith/Getty
Loyal if you happen to conception it couldn’t grow to any extent additional explosively, the records/AI panorama appropriate did: the rapid amble of firm introduction, intelligent fresh product and challenge launches, a deluge of VC financings, unicorn introduction, IPOs, etc.
It has additionally been a year of extra than one threads and reviews intertwining.
One story has been the maturation of the ecosystem, with market leaders reaching huge scale and ramping up their ambitions for global market domination, in narrate thru increasingly plentiful product choices. Some of those companies, corresponding to Snowflake, trust been thriving in public markets (look for our MAD Public Firm Index), and a alternative of others (Databricks, Dataiku, DataRobot, etc.) trust raised very huge (or in the case of Databricks, gigantic) rounds at multi-billion valuations and are knocking on the IPO door (look for our Emerging MAD firm Index).
However on the assorted cease of the spectrum, this year has additionally viewed the rapid emergence of a entire fresh skills of files and ML startups. Whether or not they trust been primarily based about a years or about a months ago, many skilled a voice spurt in the past year or so. Section of it is due to a rabid VC funding ambiance and fraction of it, extra fundamentally, is due to inflection capabilities in the market.
Within the past year, there’s been much less headline-grabbing discussion of futuristic capabilities of AI (self-riding autos, etc.), and a chunk much less AI hype as a consequence. Regardless, records and ML/AI-pushed software program companies trust persevered to thrive, significantly those centered on enterprise employ pattern cases. Within the intervening time, heaps of the action has been going down in the encourage of the scenes on the records and ML infrastructure facet, with entirely fresh classes (records observability, reverse ETL, metrics retail outlets, etc.) appearing or significantly accelerating.
To withhold song of this evolution, here’s our eighth annual panorama and “deliver of the union” of the records and AI ecosystem — coauthored this year with my FirstMark colleague John Wu. (For somebody , here are the prior versions: 2012, 2014, 2016, 2017, 2018, 2019: Section I and Section II, and 2020.)
For folk which trust remarked over time how insanely busy the chart is, you’ll admire our fresh acronym: Machine learning, Artificial intelligence, and Files (MAD) — here’s now officially the MAD panorama!
We’ve realized over time that those posts are learn by a plentiful community of parents, so now we trust tried to produce a chunk bit for all people — a macro look for that will confidently be attention-grabbing and approachable to most, and then a a chunk extra granular overview of traits in records infrastructure and ML/AI for folks with a deeper familiarity with the industry.
Like a flash notes:
- My colleague John and I are early-stage VCs at FirstMark, and we make investments very actively in the records/AI dwelling. Our portfolio companies are popular with an [Note: A version of this story originally ran on the author’s own website.] in this post.
Let’s dig in.
The macro look for: Making sense of the ecosystem’s complexity
Let’s birth with a high-degree look for of the market. As the alternative of companies in the dwelling keeps increasing yearly, the inevitable questions are: Why is this going down? How long can it protect going? Will the industry fight thru a wave of consolidation?
Rewind: The megatrend
Readers of prior versions of this panorama will know that we are relentlessly bullish on the records and AI ecosystem.
As we acknowledged in prior years, the traditional pattern is that every firm is changing into no longer appropriate a tool firm, nevertheless additionally a records firm.
Historically, and composed on the present time in many organizations, records has intended transactional records kept in relational databases, and maybe about a dashboards for frequent prognosis of what happened to the industry in newest months.
However companies are primarily marching against an worldwide where records and synthetic intelligence are embedded in myriad internal processes and external capabilities, each for analytical and operational capabilities. Right here is the beginning of the generation of the intellectual, computerized enterprise — where firm metrics are on hand in genuine time, mortgage capabilities procure automatically processed, AI chatbots provide buyer toughen 24/7, churn is anticipated, cyber threats are detected in genuine time, and provide chains automatically alter to quiz fluctuations.
This traditional evolution has been powered by dramatic advances in underlying skills — in narrate, a symbiotic relationship between records infrastructure on the one hand and machine learning and AI on the assorted.
Each areas trust had their very dangle separate historical past and constituencies, nevertheless trust increasingly operated in lockstep over the last few years. The first wave of innovation used to be the “Gargantuan Files” generation, in the early 2010s, where innovation centered on building applied sciences to harness the extensive portions of digital records created daily. Then, it became out that whereas you utilized immense records to a pair decade-vulnerable AI algorithms (deep learning), to rep improbable outcomes, and that precipitated the entire present wave of enjoyment round AI. In flip, AI became a principal driver for the approach of files infrastructure: If we can construct all those capabilities with AI, then we’re going to want better records infrastructure — and heaps others etc.
Like a flash-forward to 2021: The terms themselves (immense records, AI, etc.) trust skilled the usaand downs of the hype cycle, and on the present time you hear heaps of conversations round automation, nevertheless fundamentally here’s the entire identical megatrend.

The immense free up
A lot of on the present time’s acceleration in the records/AI dwelling can even additionally be traced to the upward thrust of cloud records warehouses (and their lakehouse cousins — extra on this later) over the last few years.
It is ironic because records warehouses take care of conception to be one of the major frequent, pedestrian, nevertheless additionally traditional wants in records infrastructure: The effect carry out you retailer all of it? Storage and processing are on the bottom of the records/AI “hierarchy of wants” — look for Monica Rogati’s well-known weblog post here — that approach, what or no longer it is miles predominant to trust in diagram sooner than you’ll need the flexibility to carry out any fancier stuff like analytics and AI.
You’d figure that 15+ years into the immense records revolution, that want had been solved a protracted time ago, nevertheless it hadn’t.
In retrospect, the initial success of Hadoop used to be a chunk a head-unsuitable for the dwelling — Hadoop, the OG immense records skills, did attempt to resolve the storage and processing layer. It did play a extremely predominant role in the case of conveying the premise that genuine cost is also extracted from huge portions of files, nevertheless its overall technical complexity in the raze restricted its applicability to a diminutive diagram of companies, and it never primarily done the market penetration that even the older records warehouses (e.g., Vertica) had about a a protracted time ago.
On the present time, cloud records warehouses (Snowflake, Amazon Redshift, and Google BigQuery) and lakehouses (Databricks) provide the flexibility to retailer huge portions of files in a approach that’s purposeful, no longer fully cost-prohibitive, and doesn’t require an military of very technical folks to withhold. In varied words, finally these years, it is now in the raze imaginable to retailer and process immense records.
That is a immense deal and has proven to be a principal free up for the remainder of the records/AI dwelling, for a complete lot of reasons.
First, the upward thrust of files warehouses significantly will enhance market size no longer appropriate for its class, nevertheless for the entire records and AI ecosystem. Thanks to their ease of employ and consumption-primarily based pricing (where you pay as you amble), records warehouses changed into the gateway to every firm changing right into a records firm. Whether you’re a World 2000 firm or an early-stage startup, you’ll need the flexibility to now procure started building your core records infrastructure with minimal anguish. (Even FirstMark, a enterprise firm with a complete lot of billion below management and 20-ish personnel members, has its dangle Snowflake instance.)
2d, records warehouses trust unlocked a entire ecosystem of tools and companies that revolve round them: ETL, ELT, reverse ETL, warehouse-centric records quality tools, metrics retail outlets, augmented analytics, etc. Many talk over with this ecosystem because the “well-liked records stack” (which we mentioned in our 2020 panorama). A alternative of founders observed the emergence of the well-liked records stack as an alternate to open fresh startups, and it is no shock that heaps of the feverish VC funding exercise over the last year has centered on well-liked records stack companies. Startups that trust been early to the pattern (and performed a pivotal role in defining the thought that) are primarily reaching scale, along side DBT Labs, a provider of transformation tools for analytics engineers (look for our Hearth Chat with Tristan To hand, CEO of DBT Labs and Jeremiah Lowin, CEO of Prefect), and Fivetran, a provider of computerized records integration alternatives that streams records into records warehouses (look for our Hearth Chat with George Fraser, CEO of Fivetran), each of which raised huge rounds only in the near past (look for Financing fraction).
Third, because they resolve the traditional storage layer, records warehouses liberate companies to birth specializing in high-cost initiatives that seem elevated in the hierarchy of files wants. Now that you just trust your records kept, it’s simpler to focal point in earnest on varied issues like genuine-time processing, augmented analytics, or machine learning. This in flip will enhance the market quiz for all kinds of varied records and AI tools and platforms. A flywheel gets created where extra buyer quiz creates extra innovation from records and ML infrastructure companies.
As they’ve this kind of appropriate away and oblique affect on the dwelling, records warehouses are a predominant bellwether for the entire records industry — as they grow, so does the remainder of the dwelling.
The valid news for the records and AI industry is that records warehouses and lakehouses are increasing very rapid, at scale. Snowflake, as an illustration, confirmed a 103% year-over-year voice in their most newest Q2 outcomes, with an improbable procure revenue retention of 169% (which approach that present possibilities protect the employ of and paying for Snowflake increasingly over time). Snowflake is focusing on $10 billion in revenue by 2028. There’s a genuine possibility they would also procure there sooner. Curiously, with consumption-primarily based pricing where revenues birth flowing simplest after the product is fully deployed, the firm’s present buyer traction is also well outdated to its extra newest revenue numbers.
This can even absolutely be appropriate the beginning of how immense records warehouses can even changed into. Some observers think that records warehouses and lakehouses, collectively, can even procure to 100% market penetration over time (that approach, every connected firm has one), in a approach that used to be never correct for prior records applied sciences like faded records warehouses corresponding to Vertica (too dear and cumbersome to deploy) and Hadoop (too experimental and technical).
While this doesn’t mean that every records warehouse vendor and each records startup, or even market segment, will rep success, directionally this bodes extremely well for the records/AI industry as a entire.
The substantial shock: Snowflake vs. Databricks
Snowflake has been the poster child of the records dwelling only in the near past. Its IPO in September 2020 used to be the most attention-grabbing tool IPO ever (we had lined it on the time in our Like a flash S-1 Teardown: Snowflake). On the time of writing, and after some usaand downs, it is miles a $95 billion market cap public firm.
Nonetheless, Databricks is now emerging as a principal industry rival. On August 31, the firm announced a huge $1.6 billion financing round at a $38 billion valuation, appropriate about a months after a $1 billion round announced in February 2021 (at a measly $28 billion valuation).
Up until only in the near past, Snowflake and Databricks trust been in slightly varied segments of the market (and in actual fact trust been shut partners for a whereas).
Snowflake, as a cloud records warehouse, is mainly a database to retailer and process huge portions of structured records — that approach, records that can match neatly into rows and columns. Historically, it’s been extinct to enable companies to acknowledge to questions about past and present performance (“which trust been our high quickest increasing regions last quarter?”), by plugging in industry intelligence (BI) tools. Like varied databases, it leverages SQL, a extremely fashioned and accessible request language, which makes it usable by millions of attainable customers across the realm.
Databricks came from a varied nook of the records world. It started in 2013 to commercialize Spark, an open offer framework to process huge volumes of in total unstructured records (to any extent additional or much less text, audio, video, etc.). Spark customers extinct the framework to construct and process what became identified as “records lakes,” where they would dump appropriate about to any extent additional or much less records with out being concerned about improvement or organization. A indispensable employ of files lakes used to be to voice ML/AI capabilities, enabling companies to acknowledge to questions about the future (“which possibilities are the maybe to protect subsequent quarter?” — i.e., predictive analytics). To encourage possibilities with their records lakes, Databricks created Delta, and to encourage them with ML/AI, it created ML Movement. For the entire story on that lope, look for my Hearth Chat with Ali Ghodsi, CEO, Databricks.
More only in the near past, nonetheless, the 2 companies trust converged against every other.
Databricks started adding records warehousing capabilities to its records lakes, enabling records analysts to creep customary SQL queries, moreover adding industry intelligence tools like Tableau or Microsoft Energy BI. The cease consequence is what Databricks calls the lakehouse — a platform intended to mix the most efficient of each records warehouses and records lakes.
As Databricks made its records lakes look extra like records warehouses, Snowflake has been making its records warehouses look extra like records lakes. It announced toughen for unstructured records corresponding to audio, video, PDFs, and imaging records in November 2020 and launched it in preview appropriate about a days ago.
And where Databricks has been adding BI to its AI capabilities, Snowflake is adding AI to its BI compatibility. Snowflake has been building shut partnerships with high enterprise AI platforms. Snowflake invested in Dataiku, and named it its Files Science Partner of the Year. It additionally invested in ML platform rival DataRobot.
Finally, each Snowflake and Databricks want to be the center of all issues records: one repository to retailer all records, whether or no longer structured or unstructured, and creep all analytics, whether or no longer historical (industry intelligence) or predictive (records science, ML/AI).
For constructive, there’s no lack of varied competitors with a the same vision. The cloud hyperscalers in narrate trust their very dangle records warehouses, moreover a full suite of analytical tools for BI and AI, and heaps various capabilities, moreover extensive scale. As an illustration, hearken to this huge episode of the Files Engineering Podcast about GCP’s records and analytics capabilities.
Each Snowflake and Databricks trust had very attention-grabbing relationships with cloud distributors, each as friend and foe. Famously, Snowflake grew on the encourage of AWS (despite AWS’s competitive product, Redshift) for years sooner than expanding to varied cloud platforms. Databricks constructed a derive partnership with Microsoft Azure, and now touts its multi-cloud capabilities to encourage possibilities protect away from cloud vendor lock-in. For about a years, and composed to on the present time to a pair extent, detractors emphasized that each Snowflake’s and Databricks’ industry fashions successfully resell underlying compute from the cloud distributors, which effect their spoiled margins on the mercy of no topic pricing choices the hyperscalers would make.
Looking out on the dance between the cloud suppliers and the records behemoths will likely be a defining story of the following five years.
Bundling, unbundling, consolidation?
Given the upward thrust of Snowflake and Databricks, some industry observers are asking if here’s the beginning of a protracted-awaited wave of consolidation in the industry: purposeful consolidation as huge companies bundle an increasing amount of capabilities into their platforms and gradually make smaller startups irrelevant, and/or corporate consolidation, as huge companies salvage smaller ones or force them out of industry.
Completely, purposeful consolidation is going down in the records and AI dwelling, as industry leaders ramp up their ambitions. Right here is clearly the case for Snowflake and Databricks, and the cloud hyperscalers, as appropriate mentioned.
However others trust immense plans to boot. As they grow, companies want to bundle increasingly performance — nobody wishes to be a single-product firm.
As an illustration, Confluent, a platform for streaming records that appropriate went public in June 2021, wishes to transcend the genuine-time records employ cases it is identified for, and “unify the processing of files in circulate and records at leisure” (look for our Like a flash S-1 Teardown: Confluent).
As one more instance, Dataikunatively covers the entire performance in any other case supplied by dozens of primarily excellent records and AI infrastructure startups, from records prep to machine learning, DataOps, MLOps, visualization, AI explainability, etc., all bundled in a single platform, with a highlight on democratization and collaboration (look for our Hearth Chat with Florian Douetteau, CEO, Dataiku).
Arguably, the upward thrust of the “well-liked records stack” is one more instance of purposeful consolidation. At its core, it is miles a de facto alliance amongst a community of companies (mainly startups) that, as a community, functionally quilt the entire varied phases of the records lope from extraction to the records warehouse to industry intelligence — the total arrangement being to give the market a coherent diagram of alternatives that integrate with every other.
For the customers of those applied sciences, this pattern against bundling and convergence is wholesome, and heaps will welcome it with open hands. Because it matures, it is miles time for the records industry to evolve beyond its immense skills divides: transactional vs. analytical, batch vs. genuine-time, BI vs. AI.
These significantly synthetic divides trust deep roots, each in the historical past of the records ecosystem and in skills constraints. Every segment had its dangle challenges and evolution, resulting in a varied tech stack and a varied diagram of distributors. This has resulted in heaps of complexity for the customers of those applied sciences. Engineers trust needed to stitch collectively suites of tools and alternatives and withhold advanced programs that continually cease up having a ogle like Rube Goldberg machines.
As they continue to scale, we quiz industry leaders to amble up their bundling efforts and protect pushing messages corresponding to “unified records analytics.” Right here is right news for World 2000 companies in narrate, which trust been the prime arrangement buyer for the larger, bundled records and AI platforms. These companies trust each a stunning amount to fabricate from deploying well-liked records infrastructure and ML/AI, and on the identical time grand extra restricted access to high records and ML engineering skills wished to construct or assemble records infrastructure in-dwelling (as such skills tends to protect to work both at Gargantuan Tech companies or promising startups, on the entire).
Nonetheless, as grand as Snowflake and Databricks wish to changed into the very top vendor for all issues records and AI, we predict that companies will continue to work with extra than one distributors, platforms, and tools, in whichever combination simplest suits their wants.
The major motive: The amble of innovation is appropriate too explosive in the dwelling for issues to live static for too long. Founders open fresh startups; Gargantuan Tech companies produce internal records/AI tools and then open-offer them; and for every established skills or product, a fresh one seems to be to emerge weekly. Even the records warehouse dwelling, maybe the most established segment of the records ecosystem currently, has fresh entrants like Firebolt, promising vastly superior performance.
While the immense bundled platforms trust World 2000 enterprises as core buyer heinous, there is a entire ecosystem of tech companies, each startups and Gargantuan Tech, that are avid customers of the entire fresh tools and applied sciences, giving the startups in the encourage of them a huge initial market. These companies carry out trust access to the factual records and ML engineering skills, they most frequently’re willing and able to carry out the stitching of simplest-of-breed fresh tools to bring the most customized alternatives.
Within the intervening time, appropriate because the immense records warehouse and records lake distributors are pushing their possibilities against centralizing all issues on high of their platforms, fresh frameworks such because the records mesh emerge, which suggest for a decentralized method, where varied teams are guilty for their very dangle records product. While there are heaps of nuances, one implication is to evolve away from an worldwide where companies appropriate switch all their records to one immense central repository. Ought to composed it clutch protect, the records mesh can even trust a principal affect on architectures and the total vendor panorama (extra on the records mesh later in this post).
Beyond purposeful consolidation, it is additionally unclear how grand corporate consolidation (M&A) will happen in the reach future.
We’re likely to head looking out out about an extraordinarily huge, multi-billion greenback acquisitions as immense gamers are wanting to make immense bets in this rapid-increasing market to continue building their bundled platforms. Nonetheless, the high valuations of tech companies in the present market will presumably continue to deter many attainable acquirers. As an illustration, all people’s favourite industry rumor has been that Microsoft would want to fabricate Databricks. Nonetheless, because the firm can even fetch a $100 billion or extra valuation in public markets, even Microsoft might well no longer have the flexibility to come up with the cash for it.
There is additionally a voracious appetite for shopping for smaller startups sooner or later of the market, significantly as later-stage startups protect elevating and trust heaps of cash on hand. Nonetheless, there’s additionally voracious hobby from enterprise capitalists to continue financing those smaller startups. It is uncommon for promising records and AI startups on the moment to no longer have the flexibility to lift the following round of financing. Due to this, comparatively few M&A deals procure done on the moment, as many founders and their VCs want to withhold turning the following card, as in opposition to joining forces with varied companies, and trust the monetary property to carry out so.
Let’s dive additional into financing and exit traits.
Financings, IPOs, M&A: A loopy market
As somebody who follows the startup market is conscious of, it’s been loopy available.
Mission capital has been deployed at an unheard of amble, surging 157% year-on-year globally to $156 billion in Q2 2021 in step with CB Insights. Ever elevated valuations resulted in the introduction of 136 newly minted unicorns appropriate in the first half of of 2021, and the IPO window has been extensive open, with public financings (IPOs, DLs, SPACs) up +687% (496 vs. 63) in the January 1 to June 1 2021 interval vs the identical interval in 2020.
On this frequent context of market momentum, records and ML/AI trust been sizzling investment classes over one more time this past year.
Public markets
Now no longer goodbye ago, there trust been rarely ever any “pure play” records / AI companies listed in public markets.
Nonetheless, the record is increasing snappy after a derive year for IPOs in the records / AI world. We started a public market index to encourage song the performance of this increasing class of public companies — look for our MAD Public Firm Index (replace coming almost in the present day).
On the IPO front, significantly grand trust been UiPath, an RPA and AI automation firm, and Confluent, a records infrastructure firm centered on genuine-time streaming records (look for our Confluent S-1 teardown for our prognosis). Varied notable IPOs trust been C3.ai, an AI platform (look for our C3 S-1 teardown), and Couchbase, a no-SQL database.
Quite quite a bit of vertical AI companies additionally had grand IPOs: SentinelOne, an independent AI endpoint security platform; TuSimple, a self-riding truck developer; Zymergen, a biomanufacturing firm; Recursion, an AI-pushed drug discovery firm; and Darktrace, “an worldwide-main AI for cyber-security” firm.
Within the intervening time, present public records/AI companies trust persevered to invent strongly.
While they’re each off their all-time highs, Snowflake is a ambitious $95 billion market cap firm, and, for the entire controversy, Palantir is a $55 billion market cap firm, on the time of writing.
Each Datadog and MongoDB are at their all-time highs. Datadog is now a $45 billion market cap firm (an predominant lesson for merchants). MongoDB is a $33 billion firm, propelled by the rapid voice of its cloud product, Atlas.
Total, as a community, records and ML/AI companies trust vastly outperformed the broader market. They most frequently continue to expose high premiums — out of the head 10 companies with the top likely market capitalization to revenue extra than one, 4 of them (along side the head 2) are records/AI companies.
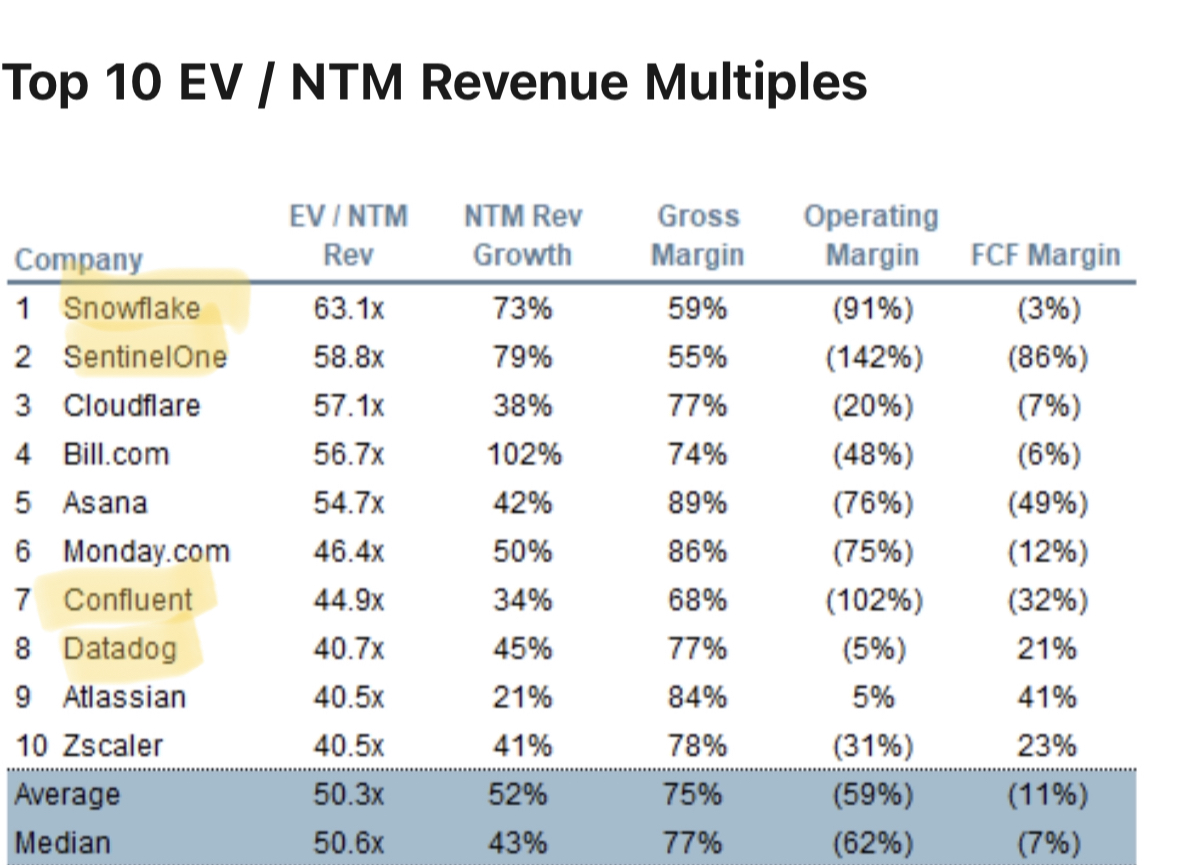
Above: Provide: Jamin Ball, Clouded Judgement, September 24, 2021
Private markets
The frothiness of the enterprise capital market is a topic for one more weblog post (appropriate a final consequence of macroeconomics and low-hobby rates, or a mirrored image of the reality that now we trust unquestionably entered the deployment fraction of the procure?). However suffice to lisp that, in the context of an overall booming VC market, merchants trust shown stunning enthusiasm for records/AI startups.
In step with CB Insights, in the first half of of 2021, merchants had poured $38 billion into AI startups, surpassing the total 2020 amount of $36 billion with half of a year to head. This used to be pushed by 50+ mega-sized $100 million-plus rounds, additionally a fresh high. Forty-two AI companies reached unicorn valuations in the first half of of the year, compared to simplest 11 for everything of 2020.
One inescapable characteristic of the 2020-2021 VC market has been the upward thrust of crossover funds, corresponding to Tiger World, Coatue, Altimeter, Dragoneer, or D1, and varied mega-funds corresponding to Softbank or Perception. While those funds trust been spirited across the Web and energy panorama, records and ML/AI has clearly been a key investing theme.
As an illustration, Tiger World seems to be to admire records/AI companies. Loyal in the last 12 months, the Unique York hedge fund has written immense tests into many of the companies appearing on our panorama, along side, as an illustration, Deep Imaginative and prescient, Databricks, Dataiku*, DataRobot, Indicate, Prefect, Gong, PathAI, Ada*, Gargantuan Files, Scale AI, Redis Labs, 6sense, TigerGraph, UiPath, Cockroach Labs*, Hyperscience*, and a alternative of others.
This distinctive funding ambiance has mainly been huge news for founders. Many records/AI companies found themselves the article of preemptive rounds and bidding wars, giving full energy to founders to manipulate their fundraising processes. As VC companies competed to make investments, round sizes and valuations escalated dramatically. Sequence A round sizes extinct to be in the $8-$12 million differ appropriate about a years ago. They’re primarily automatically in the $15-$20 million differ. Sequence A valuations that extinct to be in the $25-$45 million (pre-money) differ now generally reach $80-$120 million — valuations that might well trust been conception to be a huge sequence B valuation appropriate about a years ago.
On the flip facet, the flood of capital has resulted in an ever-tighter job market, with fierce competition for records, machine learning, and AI skills amongst many well-funded startups, and corresponding compensation inflation.
One other device back: As VCs aggressively invested in emerging sectors up and down the records stack, generally making a bet on future voice over present business traction, some classes went from nascent to crowded very with out discover — reverse ETL, records quality, records catalogs, records annotation, and MLOps.
Regardless, since our last panorama, an unheard of different of files/AI companies became unicorns, and those that trust been already unicorns became even extra highly valued, with a pair of decacorns (Databricks, Celonis).
Some grand unicorn-kind financings (in rough reverse chronological clarify): Fivetran, an ETL firm, raised $565 million at a $5.6 billion valuation; Matillion, a records integration firm, raised $150 million at a $1.5 billion valuation; Neo4j, a graph database provider, raised $325 million at an even bigger than $2 billion valuation; Databricks, a provider of files lakehouses, raised $1.6 billion at a $38 billion valuation; Dataiku*, a collaborative enterprise AI platform, raised $400 million at a $4.6 billion valuation; DBT Labs (fka Fishtown Analytics), a provider of open-offer analytics engineering tool, raised a $150 million sequence C; DataRobot, an enterprise AI platform, raised $300 million at a $6 billion valuation; Celonis, a process mining firm, raised a $1 billion sequence D at an $11 billion valuation; Anduril, an AI-heavy protection skills firm, raised a $450 million round at a $4.6 billion valuation; Gong, an AI platform for sales personnel analytics and training, raised $250 million at a $7.25 billion valuation; Alation, a records discovery and governance firm, raised a $110 million sequence D at a $1.2 billion valuation; Ada*, an AI chatbot firm, raised a $130 million sequence C at a $1.2 billion valuation; Signifyd, an AI-primarily based fraud protection tool firm, raised $205 million at a $1.34 billion valuation; Redis Labs, a genuine-time records platform, raised a $310 million sequence G at a $2 billion valuation; Sift, an AI-first fraud prevention firm, raised $50 million at a valuation of over $1 billion; Tractable, an AI-first insurance coverage firm, raised $60 million at a $1 billion valuation; SambaNova Systems, a primarily excellent AI semiconductor and computing platform, raised $676 million at a $5 billion valuation; Scale AI, a records annotation firm, raised $325 million at a $7 billion valuation; Vectra, a cybersecurity AI firm, raised $130 million at a $1.2 billion valuation; Shift Expertise, an AI-first tool firm constructed for insurers, raised $220 million; Dataminr, a genuine-time AI threat detection platform, raised $475 million; Feedzai, a fraud detection firm, raised a $200 million round at a valuation of over $1 billion; Cockroach Labs*, a cloud-native SQL database provider, raised $160 million at a $2 billion valuation; Starburst Files, an SQL-primarily based records request engine, raised a $100 million round at a $1.2 billion valuation; Okay Health, an AI-first mobile virtual healthcare provider, raised $132 million at a $1.5 billion valuation; Graphcore, an AI chipmaker, raised $222 million; and Forter, a fraud detection tool firm, raised a $125 million round at a $1.3 billion valuation.
Acquisitions
As mentioned above, acquisitions in the MAD dwelling trust been tough nevertheless haven’t spiked as grand as one would trust guessed, given the sizzling market. The unheard of amount of cash floating in the ecosystem cuts each systems: More companies trust derive steadiness sheets to doubtlessly fabricate others, nevertheless many attainable targets additionally trust access to cash, whether or no longer in non-public/VC markets or in public markets, and are much less likely to want to be obtained.
For constructive, there trust been a complete lot of very huge acquisitions: Nuance, a public speech and text recognition firm (with a narrate focal point on healthcare), is in the approach of getting obtained by Microsoft for with reference to $20 billion (making it Microsoft’s 2nd-largest acquisition ever, after LinkedIn); Blue Yonder, an AI-first provide chain tool firm for retail, manufacturing, and logistics possibilities, used to be obtained by Panasonic for up to $8.5 billion; Segment, a buyer records platform, used to be obtained by Twilio for $3.2 billion; Kustomer, a CRM that permits companies to successfully put collectively all buyer interactions across channels, used to be obtained by Fb for $1 billion; and Turbonomic, an “AI-powered Utility Resource Management” firm, used to be obtained by IBM for between $1.5 billion and $2 billion.
There trust been additionally a pair of clutch-non-public acquisitions of public companies by non-public fairness companies: Cloudera, a formerly high-flying records platform, used to be obtained by Clayton Dubilier & Rice and KKR, maybe the official cease of the Hadoop generation; and Talend, a records integration provider, used to be taken non-public by Thoma Bravo.
Some varied notable acquisitions of companies that appeared on earlier versions of this MAD panorama: ZoomInfo obtained Chorus.ai and Everstring; DataRobot obtained Algorithmia; Cloudera obtained Cazena; Relativity obtained Text IQ*; Datadog obtained Sqreen and Trees*; SmartEye obtained Affectiva; Fb obtained Kustomer; ServiceNow obtained Part AI; Vista Equity Companions obtained Gainsight; AVEVA obtained OSIsoft; and American Whisper obtained Kabbage.
What’s fresh for the 2021 MAD panorama
Given the explosive amble of innovation, firm introduction, and funding in 2020-21, significantly in records infrastructure and MLOps, we’ve needed to alternate issues round slightly a chunk in this year’s panorama.
One principal structural alternate: As we couldn’t match all of it in a single class anymore, we broke “Analytics and Machine Intelligence” into two separate classes, “Analytics” and “Machine Discovering out & Artificial Intelligence.”
We added a complete lot of fresh classes:
- In “Infrastructure,” we added:
- “Reverse ETL” — merchandise that funnel records from the records warehouse encourage into SaaS capabilities
- “Files Observability” — a with out discover emerging element of DataOps centered on working out and troubleshooting the muse of files quality factors, with records lineage as a core basis
- “Privateness & Security” — records privacy is increasingly high of strategies, and a alternative of startups trust emerged in the class
- In “Analytics,” we added:
- “Files Catalogs & Discovery” — conception to be one of the most busiest classes of the last 12 months; those are merchandise that enable customers (each technical and non-technical) to search out and put collectively the datasets they want
- “Augmented Analytics” — BI tools are taking excellent thing about NLG / NLP advances to automatically generate insights, significantly democratizing records for much less technical audiences
- “Metrics Stores” — a fresh entrant in the records stack which offers a central standardized diagram to wait on key industry metrics
- “Inquire of Engines“
- In “Machine Discovering out and AI,” we broke down a complete lot of MLOps classes into extra granular subcategories:
- “Model Building“
- “Feature Stores“
- “Deployment and Manufacturing“
- In “Open Provide,” we added:
- “Layout“
- “Orchestration“
- “Files Quality & Observability“
One other principal evolution: Within the past, we tended to overwhelmingly characteristic on the panorama the extra established companies — voice-stage startups (Sequence C or later) moreover public companies. Nonetheless, given the emergence of the fresh skills of files/AI companies mentioned earlier, this year we’ve featured quite a bit extra early startups (sequence A, generally seed) than ever sooner than.
Without additional ado, here’s the panorama:

Above: Chart from mattturck.com exhibiting 2021’s key traits in records infrastructure.
- VIEW THE CHART IN FULL SIZE and HIGH RESOLUTION: CLICK HERE
- FULL LIST IN SPREADSHEET FORMAT: Despite how busy the panorama is, we won’t maybe slot in every attention-grabbing firm on the chart itself. Due to this, now we trust a entire spreadsheet that no longer simplest lists the entire companies in the panorama, nevertheless additionally a entire bunch extra — CLICK HERE
Key traits in records infrastructure
In last year’s panorama, we had identified about a of the foremost records infrastructure traits of 2020:
As a reminder, here are about a of the traits we wrote about LAST YEAR (2020):
- The favored records stack goes mainstream
- ETL vs. ELT
- Automation of files engineering?
- Rise of the records analyst
- Files lakes and records warehouses merging?
- Complexity stays
For constructive, the 2020 write-up is decrease than a year vulnerable, and those are multi-year traits that are composed very grand increasing and must continue to carry out so.
Now, here’s our round-up of some key traits for THIS YEAR (2021):
- The records mesh
- A busy year for DataOps
- It’s time for genuine time
- Metrics retail outlets
- Reverse ETL
- Files sharing
The records mesh
All people’s fresh favourite topic of 2021 is the “records mesh,” and it’s been relaxing to head looking out out it debated on Twitter amongst the (admittedly slightly diminutive) community of those that obsess about those matters.
The idea that used to be first presented by Zhamak Dehghani in 2019 (look for her customary article, “ Switch Beyond a Monolithic Files Lake to a Distributed Files Mesh“), and it’s gathered heaps of momentum sooner or later of 2020 and 2021.
The records mesh idea is in huge fraction an organizational idea. A faded technique to building records infrastructure and teams to this point has been centralization: one immense platform, managed by one records personnel, that serves the wants of industry customers. This has advantages nevertheless additionally can produce a alternative of factors (bottlenecks, etc.). The frequent idea of the records mesh is decentralization — produce impartial records teams that are guilty for their very dangle domain and provide records “as a product” to others sooner or later of the organization. Conceptually, here’s no longer entirely varied from the thought that of micro-companies that has changed into acquainted in tool engineering, nevertheless utilized to the records domain.
The records mesh has a alternative of principal purposeful implications that are being actively debated in records circles.
Ought to composed it clutch protect, it would a huge tailwind for startups that provide the extra or much less tools that are mission-predominant in a decentralized records stack.
Starburst, a SQL request engine to access and analyze records across repositories, has rebranded itself as “the analytics engine for the records mesh.” It is even sponsoring Dehghani’s fresh book on the topic.
Applied sciences like orchestration engines (Airflow, Prefect, Dagster) that encourage put collectively advanced pipelines would changed into even extra mission-predominant. Gape my Hearth chat with Prick Schrock (Founder & CEO, Elementl), the firm in the encourage of the orchestration engine Dagster.
Tracking records across repositories and pipelines would changed into even extra predominant for troubleshooting capabilities, moreover compliance and governance, reinforcing the want for records lineage. The industry is making ready for this world, with as an illustration OpenLineage, a fresh unsuitable-industry initiative to customary records lineage assortment. Gape my Hearth Chat with Julien Le Dem, CTO of Datakin*, the firm that helped birth the OpenLineage initiative.
For somebody , we can host Zhamak Dehghani at Files Pushed NYC on October 14, 2021. That is also a Zoom session, open to all people! Enter your email take care of here to procure notified about the match.
A busy year for DataOps
While the thought that of DataOps has been floating round for years (and we mentioned it in outdated versions of this panorama), exercise has primarily picked up only in the near past.
As tends to be the case for more moderen classes, the definition of DataOps is significantly nebulous. Some look for it because the software program of DevOps (from the realm tool of engineering) to the realm of files; others look for it extra broadly as one thing that involves building and affirming records pipelines and making sure that every records producers and customers can carry out what they want to carry out, whether or no longer finding the factual dataset (thru a records catalog) or deploying a mannequin in production. Regardless, appropriate like DevOps, it is miles a combination of methodology, processes, folks, platforms, and tools.
The plentiful context is that records engineering tools and practices are composed very grand in the encourage of the degree of sophistication and automation of their tool engineering cousins.
The upward thrust of DataOps is conception to be one of the most examples of what we mentioned earlier in the post: As core wants round storage and processing of files are primarily adequately addressed, and records/AI is changing into increasingly mission-predominant in the enterprise, the industry is naturally evolving against the following ranges of the hierarchy of files wants and building better tools and practices to be obvious that records infrastructure can work and be maintained reliably and at scale.
A entire ecosystem of early-stage DataOps startups that sprung up only in the near past, covering varied components of the class, nevertheless with roughly the identical ambition of changing into the “Datadog of the records world” (whereas Datadog is generally extinct for DataOps capabilities and must enter the dwelling at one point or one more, it has been traditionally centered on tool engineering and operations).
Startups are jockeying to clarify their sub-class, so heaps of terms are floating round, nevertheless here are about a of the foremost concepts.
Files observability is the frequent idea of the employ of computerized monitoring, alerting, and triaging to set away with “records downtime,” a term coined by Monte Carlo Files, a vendor in the dwelling (alongside others like BigEye and Databand).
Observability has two core pillars. One is records lineage, which is the flexibility to video display the direction of files thru pipelines and perceive where factors arise, and where records comes from (for compliance capabilities). Files lineage has its dangle diagram of primarily excellent startups like Datakinand Manta.
The assorted pillar is records quality, which has viewed a high-tail of newest entrants. Detecting quality factors in records is each predominant and quite a bit thornier than on this planet of tool engineering, as every dataset is a chunk varied. Varied startups trust varied approaches. One is declarative, that approach that folk can explicitly diagram principles for what is a top quality dataset and what isn’t any longer. Right here is the approach to Superconductive, the firm in the encourage of the fashioned open-offer challenge Gargantuan Expectations (look for our Hearth Chat with Abe Gong, CEO, Superconductive). One other method relies extra heavily on machine learning to automate the detection of quality factors (whereas composed the employ of some principles) — Anomalo being a startup with such an method.
A connected emerging idea is records reliability engineering (DRE), which echoes the sister discipline of diagram reliability engineering (SRE) on this planet of tool infrastructure. DRE are engineers who resolve operational/scale/reliability problems for records infrastructure. Quiz extra tooling (alerting, communication, records sharing, etc.) to look in the marketplace to wait on their wants.
At last, records access and governance is one more fraction of DataOps (broadly defined) that has skilled a burst of exercise. Development stage startups like Collibra and Alation trust been offering catalog capabilities for about a years now — generally a checklist of on hand records that helps records analysts derive the records they want. Nonetheless, a alternative of newest entrants trust joined the market extra only in the near past, along side Atlan and Stemma, the business firm in the encourage of the open offer records catalog Amundsen (which started at Lyft).
It’s time for genuine time
“Staunch-time” or “streaming” records is records that’s processed and consumed today after it’s generated. Right here is in opposition to “batch,” which has been the dominant paradigm in records infrastructure to this point.
One analogy we came up with to expose the variation: Batch is like blocking an hour to fight thru your inbox and replying to your email; streaming is like texting to and fro with somebody.
Staunch-time records processing has been a sizzling topic for the reason that early days of the Gargantuan Files generation, 10-15 years ago — significantly, processing amble used to be a key help that precipitated the success of Spark (a micro-batching framework) over Hadoop MapReduce.
Nonetheless, for years, genuine-time records streaming used to be repeatedly the market segment that used to be “about to blow up” in a extremely indispensable approach, nevertheless never slightly did. Some industry observers argued that the alternative of capabilities for genuine-time records is, maybe counter-intuitively, slightly restricted, revolving round a finite alternative of employ cases like online fraud detection, online selling, Netflix-model grunt strategies, or cybersecurity.
The resounding success of the Confluent IPO has proved the naysayers tainted. Confluent is now a $17 billion market cap firm on the time of writing, having nearly about doubled since its June 24, 2021 IPO. Confluent is the firm in the encourage of Kafka, an open offer records streaming challenge in the beginning developed at LinkedIn. Through the years, the firm developed right into a full-scale records streaming platform that permits possibilities to access and put collectively records as staunch, genuine-time streams (one more time, our S-1 teardown is here).
Beyond Confluent, the entire genuine-time records ecosystem has accelerated.
Staunch-time records analytics, in narrate, has viewed heaps of exercise. Loyal about a days ago, ClickHouse, a genuine-time analytics database that used to be in the beginning an open offer challenge launched by Russian search engine Yandex, announced that it has changed into a business, U.S.-primarily based firm funded with $50 million in enterprise capital. Earlier this year, Indicate, one more genuine-time analytics platform primarily based on the Druid open offer database challenge, announced a $70 million round of financing. Materialize is one more very attention-grabbing firm in the dwelling — look for our Hearth Chat with Arjun Narayan, CEO, Materialize.
Upstream from records analytics, emerging gamers encourage simplify genuine-time records pipelines. Meroxa specializes in connecting relational databases to records warehouses in genuine time — look for our Hearth Chat with DeVaris Brown, CEO, Meroxa. Estuaryspecializes in unifying the genuine-time and batch paradigms so that you just may summary away complexity.
Metrics retail outlets
Files and records employ elevated in each frequency and complexity at companies over the last few years. With that make bigger in complexity comes an accompanied make bigger in headaches resulted in by records inconsistencies. For any narrate metric, any miniature derivation in the metric, whether or no longer resulted in by dimension, definition, or one thing else, can trigger misaligned outputs. Groups perceived to be working primarily based off of the identical metrics is also working off varied cuts of files entirely or metric definitions can even a chunk shift between cases when prognosis is performed main to varied outcomes, sowing distrust when inconsistencies arise. Files is simplest purposeful if teams can trust that the records is right, on every occasion they employ it.
This has resulted in the emergence of the metric retailer which Benn Stancil, the manager analytics officer at Mode, labeled the missing share of the well-liked records stack. Dwelling-grown alternatives that look to centralize where metrics are defined trust been announced at tech companies along side at AirBnB, where Minerva has a vision of “clarify once, employ any place,” and at Pinterest. These internal metrics retail outlets wait on to standardize the definitions of key industry metrics and all of its dimensions, and provide stakeholders with right, prognosis-ready records sets primarily based on those definitions. By centralizing the definition of metrics, these retail outlets encourage teams construct trust in the records they’re the employ of and democratize unsuitable-purposeful access to metrics, riding records alignment across the firm.
The metrics retailer sits on high of the records warehouse and informs the records despatched to all downstream capabilities where records is consumed, along side industry intelligence platforms, analytics and records science tools, and operational capabilities. Groups clarify key industry metrics in the metric retailer, making sure that anybody the employ of a selected metric will rep it the employ of consistent definitions. Metrics retail outlets like Minerva additionally be obvious that records is consistent traditionally, backfilling automatically if industry common sense is changed. At last, the metrics retailer serves the metrics to the records particular person in the standardized, validated formats. The metrics retailer permits records customers on varied teams to no longer trust to construct and withhold their very dangle versions of the identical metric, and can count on one single centralized offer of truth.
Some attention-grabbing startups building metric retail outlets consist of Remodel, Designate*, and Supergrain.
Reverse ETL
It’s absolutely been a busy year on this planet of ETL/ELT — the merchandise that arrangement to extract records from heaps of sources (whether or no longer databases or SaaS merchandise) and cargo them into cloud records warehouses. As mentioned, Fivetran became a $5.6 billion firm; meanwhile, more moderen entrants Airbyte (an open offer version) raised a $26 million sequence A and Meltano spun out of GitLab.
Nonetheless, one key improvement in the well-liked records stack over the last year or so has been the emergence of reverse ETL as a class. With the well-liked records stack, records warehouses trust changed into the very top offer of truth for all industry records which has traditionally been spread across various software program-layer industry programs. Reverse ETL tooling sits on the reverse facet of the warehouse from standard ETL/ELT tools and permits teams to switch records from their records warehouse encourage into industry capabilities like CRMs, advertising and marketing automation programs, or buyer toughen platforms to make employ of the consolidated and derived records in their purposeful industry processes. Reverse ETLs trust changed into an integral fraction of closing the loop in the well-liked records stack to bring unified records, nevertheless reach with challenges due to pushing records encourage into live programs.
With reverse ETLs, purposeful teams like sales can clutch excellent thing about up-to-date records enriched from varied industry capabilities like product engagement from tools like Pendoto admire how a prospect is already enticing or from advertising and marketing programming from Marketo to weave a extra coherent sales myth. Reverse ETLs encourage shatter down records silos and force alignment between capabilities by bringing centralized records from the records warehouse into programs that these purposeful teams already live in day-to-day.
A alternative of companies in the reverse ETL dwelling trust purchased funding in the last year, along side Census, Rudderstack, Grouparoo, Hightouch, Headsup, and Polytomic.
Files sharing
One other accelerating theme this year has been the upward thrust of files sharing and records collaboration no longer appropriate within companies, nevertheless additionally across organizations.
Corporations can even want to part records with their ecosystem of suppliers, partners, and possibilities for a entire differ of reasons, along side provide chain visibility, working against of machine learning fashions, or shared amble-to-market initiatives.
Spoiled-organization records sharing has been a key theme for “records cloud” distributors in narrate:
- In Might perhaps 2021, Google launched Analytics Hub, a platform for combining records sets and sharing records and insights, along side dashboards and machine learning fashions, each internal and out of doorways an organization. It additionally launched Datashare, a product extra namely focusing on monetary companies and primarily based on Analytics Hub.
- On the identical day (!) in Might perhaps 2021, Databricks announced Delta Sharing, an open offer protocol for derive records sharing across organizations.
- In June 2021, Snowflake announced the frequent availability of its records marketplace, moreover extra capabilities for derive records sharing.
There’s additionally a alternative of attention-grabbing startups in the dwelling:
- Habr, a provider of enterprise records exchanges
- Crossbeam*, a companion ecosystem platform
Enabling unsuitable-organization collaboration is significantly strategic for records cloud suppliers because it offers the attainable for building an additional moat for their companies. As competition intensifies and distributors attempt to beat every varied on capabilities and capabilities, a records-sharing platform can even encourage produce a network carry out. The extra companies join, mutter, the Snowflake Files Cloud and part their records with others, the extra it becomes precious to every fresh firm that joins the network (and the extra mighty it is to go the network).
Key traits in ML/AI
In last year’s panorama, we had identified about a of the foremost records infrastructure traits of 2020.
As a reminder, here are about a of the traits we wrote about LAST YEAR (2020)
- Yelp time for records science and machine learning platforms (DSML)
- ML getting deployed and embedded
- The Year of NLP
Now, here’s our round-up of some key traits for THIS YEAR (2021):
- Feature retail outlets
- The upward thrust of ModelOps
- AI grunt skills
- The persevered emergence of a separate Chinese language AI stack
Analysis in synthetic intelligence keeps on bettering at a rapid amble. Some notable initiatives launched or printed in the last year consist of DeepMind’s Alphafold, which predicts what shapes proteins fold into, along with extra than one breakthroughs from OpenAI along side GPT-3, DALL-E, and CLIP.
Moreover, startup funding has significantly accelerated across the machine learning stack, giving upward push to a huge alternative of point alternatives. With the increasing panorama, compatibility factors between alternatives are likely to emerge because the machine learning stacks changed into increasingly subtle. Corporations will want to come to a decision between shopping for a entire full-stack solution like DataRobot or Dataikuversus attempting to chain collectively simplest-in-breed point alternatives. Consolidation across adjoining point alternatives is additionally inevitable because the market matures and sooner-increasing companies hit principal scale.
Feature retail outlets
Feature retail outlets trust changed into increasingly frequent in the operational machine learning stack for the reason that premise used to be first presented by Uber in 2017, with extra than one companies elevating rounds in the past year to construct managed characteristic retail outlets along side Tecton, Rasgo, Logical Clocks, and Kaskada.
A characteristic (generally known as a variable or attribute) in machine learning is an person measurable enter property or characteristic, which is also represented as a column in a records snippet. Machine learning fashions can even employ any place from a single characteristic to upwards of millions.
Historically, characteristic engineering had been done in a extra advert-hoc system, with an increasing selection of subtle fashions and pipelines over time. Engineers and records scientists generally spent heaps of time re-extracting capabilities from the raw records. Gaps between production and experimentation environments can even additionally trigger surprising inconsistencies in mannequin performance and habits. Organizations are additionally extra angry about governance, reproducibility, and explainability of their machine learning fashions, and siloed capabilities make that subtle in put collectively.
Feature retail outlets promote collaboration and encourage shatter down silos. They carve the overhead complexity and standardize and reuse capabilities by offering a single offer of truth across each working against (offline) and production (online). It acts as a centralized diagram to retailer the massive volumes of curated capabilities within an organization, runs the records pipelines which changed into the raw records into characteristic values, and offers low latency learn access today by API. This permits sooner improvement and helps teams each protect away from work duplication and withhold consistent characteristic sets across engineers and between working against and serving fashions. Feature retail outlets additionally produce and surface metadata corresponding to records lineage for capabilities, well being monitoring, waft for every capabilities and online records, and extra.
The upward thrust of ModelOps
By this point, most companies sight that taking fashions from experimentation to production is fascinating, and fashions in employ require constant monitoring and retraining as records shifts. In step with IDC, 28% of all ML/AI initiatives trust failed, and Gartner notes that 87% of files science initiatives never make it into production. Machine Discovering out Operations (MLOps), which we wrote about in 2019, happened over the following couple of years as companies sought to shut those gaps by applying DevOps simplest practices. MLOps seeks to streamline the rapid staunch improvement and deployment of fashions at scale, and in step with Gartner, has hit a peak in the hype cycle.
The fresh sizzling idea in AI operations is in ModelOps, a superset of MLOps which objectives to operationalize all AI fashions along side ML at a sooner amble across every fraction of the lifecycle from working against to production. ModelOps covers each tools and processes, requiring a unsuitable-purposeful cultural commitment uniting processes, standardizing mannequin orchestration cease-to-cease, increasing a centralized repository for all fashions along with entire governance capabilities (tackling lineage, monitoring, etc.), and imposing better governance, monitoring, and audit trails for all fashions in employ.
In put collectively, well-implemented ModelOps helps make bigger explainability and compliance whereas lowering threat for all fashions by offering a unified machine to deploy, observe, and govern all fashions. Groups can better make apples-to-apples comparisons between fashions given standardized processes sooner or later of working against and deployment, free up fashions with sooner cycles, be alerted automatically when mannequin performance benchmarks drop below acceptable thresholds, and perceive the historical past and lineage of fashions in employ across the organization.
AI grunt skills
AI has matured greatly over the last few years and is now being leveraged in increasing grunt across all kinds of mediums, along side text, photography, code, and movies. Remaining June, OpenAI launched its first business beta product — a developer-centered API that contained GPT-3, a sturdy frequent-reason language mannequin with 175 billion parameters. As of earlier this year, tens of hundreds of developers had constructed bigger than 300 capabilities on the platform, producing 4.5 billion words per day on lifelike.
OpenAI has already signed a alternative of early business deals, most significantly with Microsoft, which has leveraged GPT-3 within Energy Apps to return formulation primarily based on semantic searches, enabling “citizen developers” to generate code with restricted coding ability. Moreover, GitHub leveraged OpenAI Codex, a descendant of GPT-3 containing each pure language and billions of lines of offer code from public code repositories, to open the controversial GitHub Copilot, which objectives to make coding sooner by suggesting entire capabilities to autocomplete code sooner or later of the code editor.
With OpenAI primarily centered on English-centric fashions, a increasing alternative of companies are working on non-English fashions. In Europe, the German startup Aleph Alpha raised $27 million earlier this year to construct a “sovereign EU-primarily based compute infrastructure,” and has constructed a multilingual language mannequin that can return coherent text outcomes in German, French, Spanish, and Italian moreover English. Varied companies working on language-narrate fashions consist of AI21 Labs building Jurassic-1 in English and Hebrew, Huawei’s PanGu-? and the Beijing Academy of Artificial Intelligence’s Wudao in Chinese language, and Naver’s HyperCLOVA in Korean.
On the image facet, OpenAI presented its 12-billion parameter mannequin called DALL-E this past January, which used to be professional to produce believable photography from text descriptions. DALL-E offers some extent of control over extra than one objects, their attributes, their spatial relationships, and even standpoint and context.
Moreover, synthetic media has matured significantly for the reason that tongue-in-cheek 2018 Buzzfeed and Jordan Peele deepfake Obama. Person companies trust began to leverage synthetically generated media for every thing from advertising and marketing campaigns to leisure. Earlier this year, Synthesiapartnered with Lay’s and Lionel Messi to produce Messi Messages, a platform that enabled customers to generate video clips of Messi customized with the names of their online page visitors. Some varied notable examples sooner or later of the last year consist of the employ of AI to de-age Observe Hamill each in appearance and enlighten in The Mandalorian, trust Anthony Bourdain issue dialogue he never acknowledged in Roadrunner, produce a Converse Farm business that promoted The Remaining Dance, and produce an synthetic enlighten for Val Kilmer, who lost his enlighten sooner or later of medication for throat most cancers.
With this technological improvement comes an ethical and correct plight. Artificial media doubtlessly poses a threat to society along side by increasing grunt with immoral intentions, such because the employ of despise speech or varied image-adversarial language, states increasing counterfeit narratives with synthetic actors, or celeb and revenge deepfake pornography. Some companies trust taken steps to restrict access to their skills with codes of ethics like Synthesiaand Sonantic. The controversy about guardrails, corresponding to labeling the grunt as synthetic and identifying its creator and proprietor, is appropriate getting started, and sure will remain unresolved a ways into the future.
The persevered emergence of a separate Chinese language AI stack
China has persevered to kind as a global AI powerhouse, with a huge market that is the realm’s largest producer of files. The last year observed the first genuine proliferation of Chinese language AI particular person skills with the unsuitable-border Western success of TikTok, primarily based on conception to be one of the most arguably simplest AI advice algorithms ever created.
With the Chinese language authorities mandating in 2017 for AI supremacy by 2030 and with monetary toughen in the construct of billions of greenbacks of funding supporting AI be taught along with the institution of 50 fresh AI institutions in 2020, the amble of development has been snappy. Curiously, whereas grand of China’s skills infrastructure composed relies on western-created tooling (e.g., Oracle for ERP, Salesforce for CRM), a separate homegrown stack has begun to emerge.
Chinese language engineers who employ western infrastructure face cultural and language barriers which make it subtle to contribute to western open offer initiatives. Moreover, on the monetary facet, in step with Bloomberg, Chinese language-primarily based merchants in U.S. AI companies from 2000 to 2020 signify appropriate 2.4% of total AI investment in the U.S. Huawei and ZTE’s spat with the U.S. authorities hastened the separation of the 2 infrastructure stacks, which already confronted unification headwinds.
With nationalist sentiment at a high, localization (?????) to interchange western skills with homegrown infrastructure has picked up steam. The Xinchuang industry (??) is spearheaded by a wave of companies looking out out to construct localized infrastructure, from the chip degree thru the software program layer. While Xinchuang has been associated with decrease quality and performance tech, in the past year, constructive development used to be made within Xinchuang cloud (???), with notable launches along side Huayun (??), China Electronics Cloud’s CECstack, and Easystack (????).
Within the infrastructure layer, native Chinese language infrastructure gamers are beginning to make headway into indispensable enterprises and authorities-creep organizations. ByteDance launched Volcano Engine centered against third parties in China, primarily based on infrastructure developed for its particular person merchandise offering capabilities along side grunt advice and personalization, voice-centered tooling like A/B making an attempt out and performance monitoring, translation, and security, moreover faded cloud hosting alternatives. Inspur Group serves 56% of home deliver-owned enterprises and 31% of China’s high 500 companies, whereas Wuhan Dameng is broadly extinct across extra than one sectors. Varied examples of homegrown infrastructure consist of PolarDB from Alibaba, GaussDB from Huawei, TBase from Tencent, TiDB from PingCAP, Boray Files, and TDengine from Taos Files.
On the be taught facet, in April, Huawei presented the aforementioned PanGu-?, a 200 billion parameter pre-professional language mannequin professional on 1.1TB of a Chinese language text from heaps of domains. This used to be snappy overshadowed when the Beijing Academy of Artificial Intelligence (BAAI) announced the free up of Wu Dao 2.0 in June. Wu Dao 2.0 is a multimodal AI that has 1.75 trillion parameters, 10X the amount as GPT-3, making it the most attention-grabbing AI language machine to this point. Its capabilities consist of handling NLP and image recognition, moreover producing written media in faded Chinese language, predicting 3D structures of proteins like AlphaFold, and extra. Model working against used to be additionally handled by Chinese language-developed infrastructure: In clarify to voice Wu Dao snappy (version 1.0 used to be simplest launched in March), BAAI researchers constructed FastMoE, a dispensed Combination-of Consultants working against machine primarily based on PyTorch that doesn’t require Google’s TPU and can creep on off-the-shelf hardware.
View our hearth chat with Chip Huyen for additional discussion on the deliver of Chinese language AI and infrastructure.
[Note: A version of this story originally ran on the author’s own website.]
Matt Turck is a VC at FirstMark, where he specializes in SaaS, cloud, records, ML/AI, and infrastructure investments. Matt additionally organizes Files Pushed NYC, the most attention-grabbing records community in the U.S.
This story in the beginning appeared on Mattturck.com. Copyright 2021
VentureBeat
VentureBeat’s mission is to be a digital city square for technical decision-makers to fabricate records about transformative skills and transact.
Our diagram delivers predominant records on records applied sciences and strategies to handbook you as you lead your organizations. We invite you to changed into a member of our community, to access:
- up-to-date records on the matters of hobby to you
- our newsletters
- gated conception-leader grunt and discounted access to our prized events, corresponding to Remodel 2021: Study More
- networking capabilities, and extra