Reinforcement studying competitors pushes the boundaries of embodied AI
Be a part of Remodel 2021 this July 12-16. Register for the AI match of the year.
For the reason that early a long time of man-made intelligence, humanoid robots grasp been a staple of sci-fi books, motion images, and cartoons. Yet after a long time of be taught and pattern in AI, we restful grasp nothing that comes discontinuance to The Jetsons’ Rosey the Robotic.
Right here’s because reasonably about a our intuitive planning and motor abilities — things we attach as a correct — are grand extra complex than we predict. Navigating unknown areas, discovering and picking up objects, picking routes, and planning responsibilities are complex feats we excellent take care of after we are trying and flip them into computer purposes.
Increasing robots that could well bodily sense the arena and work alongside with their atmosphere falls into the realm of embodied artificial intelligence, one in all AI scientists’ long-sought targets. And even supposing progress in the sector is restful a a ways shot from the capabilities of americans and animals, the achievements are outstanding.
In a most up-to-date pattern in embodied AI, scientists at IBM, the Massachusetts Institute of Technology, and Stanford College developed a brand unique sing that will motivate assess AI brokers’ ability to secure paths, work alongside with objects, and opinion responsibilities effectively. Titled ThreeDWorld Transport Speak, the test is a digital atmosphere that could be equipped on the Embodied AI Workshop throughout the Conference on Computer Vision and Pattern Recognition, held on-line in June.
No most up-to-date AI tactics reach discontinuance to solving the TDW Transport Speak. Nonetheless the outcomes of the competitors can motivate expose unique instructions for the style ahead for embodied AI and robotics be taught.
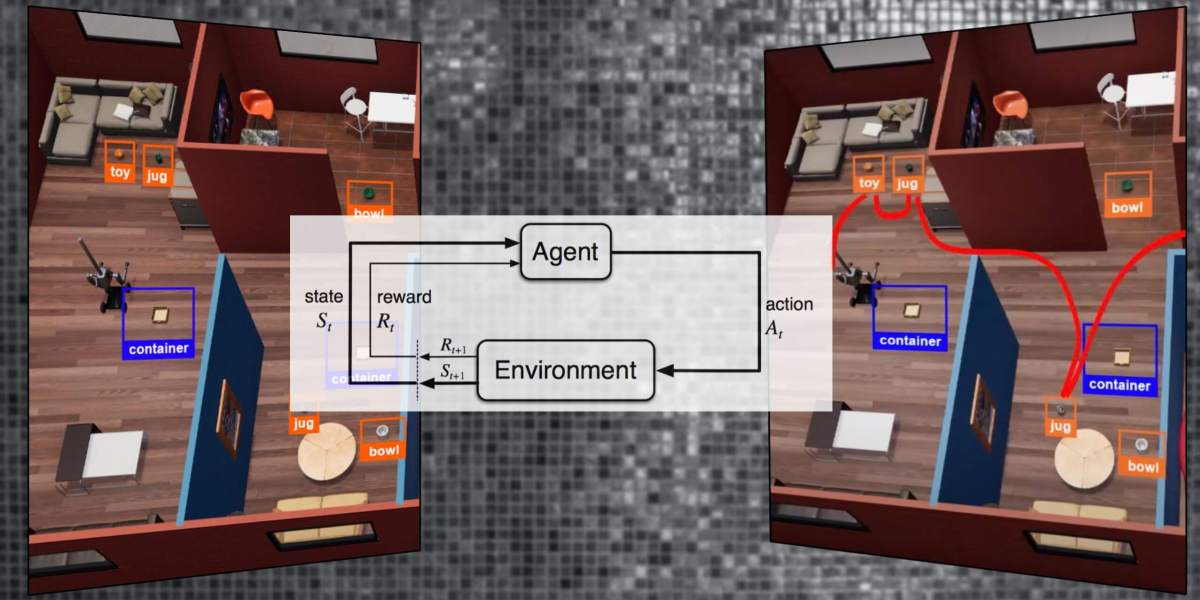
Reinforcement studying in digital environments
At the heart of most robotics purposes is reinforcement studying, a branch of machine studying in accordance to actions, states, and rewards. A reinforcement studying agent is given a attach of living of actions it is going to practice to its atmosphere to construct rewards or reach a definite aim. These actions accumulate modifications to the pronounce of the agent and the atmosphere. The RL agent receives rewards in accordance to how its actions elevate it closer to its aim.
RL brokers in general originate by shimmering nothing about their atmosphere and selecting random actions. As they step by step gather feedback from their atmosphere, they be taught sequences of actions that could well maximize their rewards.
This plan is oldschool no longer excellent in robotics, but in many assorted purposes, a lot like self-driving cars and pronounce suggestions. Reinforcement studying has moreover helped researchers master complex video games a lot like Lunge, StarCraft 2, and DOTA.
Increasing reinforcement studying items items several challenges. One of them is designing the dazzling attach of living of states, rewards, and actions, which is ready to be very tough in purposes take care of robotics, the attach brokers face a continuous atmosphere that is plagued by complex components a lot like gravity, wind, and physical interactions with assorted objects. Right here’s in distinction to environments take care of chess and Lunge which grasp very discrete states and actions.
One other sing is gathering coaching facts. Reinforcement studying brokers have to practice the employ of facts from tens of millions of episodes of interactions with their environments. This constraint can dreary robotics purposes because they have to win their facts from the physical world, versus video and board video games, which is ready to be performed in swiftly succession on several computer programs.
To overcome this barrier, AI researchers grasp tried to build up simulated environments for reinforcement studying purposes. At the novel time, self-driving cars and robotics in general employ simulated environments as a well-known piece of their coaching regime.
“Coaching items the employ of loyal robots could be dear and usually accumulate safety concerns,” Chuang Gan, essential be taught workers member on the MIT-IBM Watson AI Lab, told TechTalks. “Due to this, there has been a pattern in direction of incorporating simulators, take care of what the TDW-Transport Speak offers, to practice and desire in mind AI algorithms.”
Nonetheless replicating the categorical dynamics of the physical world is amazingly tough, and most simulated environments are a tough approximation of what a reinforcement studying agent would face in the loyal world. To tackle this limitation, the TDW Transport Speak crew has long past to good lengths to construct the test atmosphere as life like as imaginable.
The atmosphere is built on top of the ThreeDWorld platform, which the authors picture as “a well-liked-cause digital world simulation platform supporting each and each discontinuance to-characterize life like image rendering, bodily primarily based entirely sound rendering, and life like physical interactions between objects and brokers.”
“We aimed to employ a extra developed physical digital atmosphere simulator to interpret a brand unique embodied AI job requiring an agent to commerce the states of further than one objects below life like physical constraints,” the researchers write in an accompanying paper.
Assignment and circulate planning
Reinforcement studying tests grasp assorted degrees of sing. Most most up-to-date tests accumulate navigation responsibilities, the attach an RL agent have to secure its procedure thru a digital atmosphere in accordance to visual and audio input.
The TDW Transport Speak, on the assorted hand, pits the reinforcement studying brokers against “job and circulate planning” (TAMP) problems. TAMP requires the agent to no longer excellent secure optimum circulate paths but to moreover commerce the pronounce of objects to invent its aim.
The sing takes popularity in a multi-roomed house embellished with furniture, objects, and containers. The reinforcement studying agent views the atmosphere from a first-person standpoint and have to secure one or several objects from the rooms and win them at a specified destination. The agent is a two-armed robotic, so it is going to excellent elevate two objects at a time. Alternatively, it is going to employ a container to withhold several objects and decrease the change of trips it has to construct.
At each and each step, the RL agent can resolve one in all several actions, a lot like turning, shifting ahead, or picking up an object. The agent receives a reward if it accomplishes the switch job interior a little change of steps.
Whereas this seems take care of the extra or less dilemma any child could well well clear up with out grand coaching, it is indeed a fancy job for most up-to-date AI programs. The reinforcement studying program have to secure the dazzling steadiness between exploring the rooms, discovering optimum paths to the destination, picking between carrying objects alone or in containers, and doing all this all the device thru the designated step budget.
“By the TDW-Transport Speak, we’re proposing a brand unique embodied AI sing,” Gan acknowledged. “Namely, a robotic agent have to connect actions to circulation and commerce the pronounce of an infinite change of objects in a characterize- and bodily life like digital atmosphere, which remains a advanced aim in robotics.”
Abstracting challenges for AI brokers

Above: Within the ThreeDWorld Transport Speak, the AI agent can leer the arena thru color, depth, and segmentation maps.
Whereas TDW is a in actuality advanced simulated atmosphere, the designers grasp restful abstracted doubtless the most challenges robots would face in the loyal world. The digital robotic agent, dubbed Magnebot, has two fingers with 9 degrees of freedom and joints on the shoulder, elbow, and wrist. On the change hand, the robotic’s hands are magnets and can gain up any object with out wanting to handle it with fingers, which itself is a in actuality tough job.
The agent moreover perceives the atmosphere in three assorted programs: as an RGB-colored frame, a depth plan, and a segmentation plan that displays each and each object individually in tense colours. The depth and segmentation maps construct it less complicated for the AI agent to read the dimensions of the scene and expose the objects apart when viewing them from awkward angles.
To desire away from confusion, the concerns are posed in a straightforward structure (e.g., “vase:2, bowl:2, jug:1; mattress”) reasonably than as free language instructions (e.g., “Dangle two bowls, a pair of vases, and the jug in the mattress room, and put them all on the mattress”).
And to simplify the pronounce and circulate house, the researchers grasp little the Magnebot’s navigation to 25-centimeter movements and 15-stage rotations.
These simplifications enable builders to focal level on the navigation and job-planning problems AI brokers have to beat in the TDW atmosphere.
Gan told TechTalks that despite the phases of abstraction launched in TDW, the robotic restful needs to handle the next challenges:
- The synergy between navigation and interplay: The agent can no longer circulation to gain an object if this object is not any longer in the selfish see, or if the train path to it is obstructed.
- Physics-aware interplay: Greedy could well fail if the agent’s arm can no longer reach an object.
- Physics-aware navigation: Collision with boundaries could well motive objects to be dropped and vastly hinder transport efficiency.
This highlights the complexity of human imaginative and prescient and agency. The subsequent time you bound to a grocery store, desire in mind how with out dilemma it’s good to well well secure your procedure thru aisles, expose the variation between assorted merchandise, reach for and gain up assorted items, popularity them for your basket or cart, and resolve your path in an atmosphere friendly procedure. And you’re doing all this with out access to segmentation and depth maps and by studying items from a crumpled handwritten demonstrate for your pocket.
Pure deep reinforcement studying is not any longer adequate
![]()
Above: Experiments show mask hybrid AI items that mix reinforcement studying with symbolic planners are better suited to solving the ThreeDWorld Transport Speak.
The TDW-Transport Speak is in the center of of accepting submissions. Within the interim, the authors of the paper grasp already tested the atmosphere with several known reinforcement studying tactics. Their findings show mask that pure reinforcement studying is terribly miserable at solving job and circulate planning challenges. A pure reinforcement studying procedure requires the AI agent to form its conduct from scratch, starting with random actions and step by step refining its protection to fulfill the targets in the required change of steps.
In response to the researchers’ experiments, pure reinforcement studying approaches barely managed to surpass 10% success in the TDW tests.
“We assume this reflects the complexity of physical interplay and the large exploration search house of our benchmark,” the researchers wrote. “When put next with the old level-aim navigation and semantic navigation responsibilities, the attach the agent excellent needs to navigate to particular coordinates or objects in the scene, the ThreeDWorld Transport sing requires brokers to circulation and commerce the objects’ physical pronounce in the atmosphere (i.e., job-and-circulate planning), which the stop-to-stop items could well descend short on.”
When the researchers tried hybrid AI items, the attach a reinforcement studying agent became mixed with a rule-primarily based entirely high-stage planner, they saw a substantial enhance in the gadget’s efficiency.
“This atmosphere could be oldschool to practice RL items, which descend short on these kinds of responsibilities and require particular reasoning and planning abilities,” Gan acknowledged. “By the TDW-Transport Speak, we hope to brand that a neuro-symbolic, hybrid model can toughen this dilemma and brand a stronger efficiency.”
The dilemma, on the change hand, remains largely unsolved, and even the excellent-performing hybrid programs had round 50% success rates. “Our proposed job is terribly tough and could be oldschool as a benchmark to trace the progress of embodied AI in bodily life like scenes,” the researchers wrote.
Mobile robots have gotten a scorching house of be taught and purposes. In response to Gan, several manufacturing and dapper factories grasp already expressed hobby in the employ of the TDW atmosphere for their loyal-world purposes. This is in a position to perhaps even very effectively be attention-grabbing to leer whether or no longer the TDW Transport Speak will motivate usher unique innovations into the sector.
“We’re hopeful the TDW-Transport Speak can motivate procedure be taught round assistive robotic brokers in warehouses and residential settings,” Gan acknowledged.
This chronicle on the foundation appeared on Bdtechtalks.com. Copyright 2021
VentureBeat
VentureBeat’s mission is to be a digital town sq. for technical option-makers to build up facts about transformative expertise and transact.
Our position delivers well-known facts on facts applied sciences and recommendations to facts you as you lead your organizations. We invite you to change into a member of our community, to access:
- up-to-date facts on the issues of hobby to you
- our newsletters
- gated concept-chief pronounce and discounted access to our prized events, a lot like Remodel 2021: Learn Extra
- networking aspects, and extra