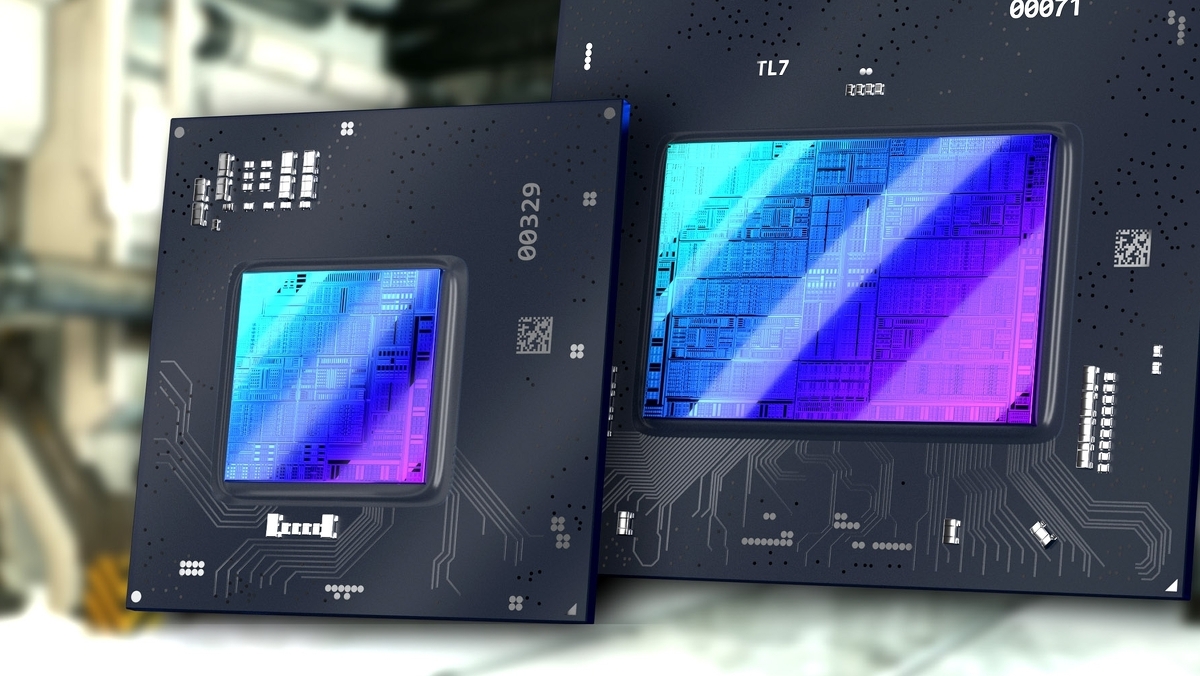
The mammoth interview: how Intel Alchemist GPUs and XeSS upscaling will change PC gaming
Last week, Intel not without extend laid down its cards. Structure Day 2021 saw the corporate ship an array of surely thrilling recent products, stretching across CPUs and graphics, from laptop to datacentre. The firm is taking a glimpse to vastly streak its compute performance by a component of 1000x over a whole lot of years. It is some distance a apparently not attainable job, nevertheless Intel wants to attain it by leveraging the cutting-edge in CPU, GPU and integration expertise. A core section of the approach is in handing over competitive graphics performance – and that is the explanation where the recent line of discrete GPUs from Intel involves the fore… and they’re taking a glimpse incredible.
Codenamed Alchemist, the recent GPU looks to connect shut Intel’s present graphics tech – notify in constructed-in develop in its Tiger Lake and in restricted start via the DG1 graphics card – and lengthen it out in all instructions. More execution items (96 in DG1, as a lot as 512 in DG2), more vitality, more memory bandwidth plus the final streak and efficiency advantages of TSMC’s recent 6nm fabrication direction of.
Digital Foundry’s Prosperous Leadbetter and Alex Battaglia focus on Intel Alchemist, XeSS upscaling – and the manner forward for graphics – in this video version of our interview.
But over and above that, there are recent aspects too. Genuinely, taking a glimpse at a block structure of the Alchemist GPU, we apparently hold a philosophy great closer to Nvidia’s products in want to AMD’s. The place Group Red centered on rasterisation performance and memory bandwidth optimisations over hardware acceleration RT and machine discovering out aspects, Intel offers a steadiness great closer to the GeForce line, with vastly more silicon dedicated to those subsequent-gen aspects.
But those aspects should always be mature, clearly, and that is clarification why Intel’s repeat of XeSS is so vital. Based fully on the slides and recordsdata gleaned from Structure Day (and this interview), Intel appears to be like to be following the identical ability as Nvidia with its hold DLSS 2.x expertise. Nonetheless, the approach in its deployment may per chance be very numerous – Intel wants to standardise machine discovering out-essentially essentially based mostly expansive-sampling, it has no passion in making it proprietary in the manner that Nvidia does with DLSS. XeSS will work on a fluctuate of GPUs from a fluctuate of vendors, which is precisely the right kind approach to make certain that that the expertise becomes section and parcel of PC gaming.
And all of that lays the muse for this interview, edited for clarity, where myself and #FriendAndColleague Alex Battaglia quizzed Intel vice chairman and head of graphics tool Lisa Pearce along with engineering fellow Tom Petersen about what to sit down up for from Alchemist, aesthetic how begin and standardised XeSS will surely be, the work the firm has carried out with the tool stack and the device in which the manner forward for graphics looks from Intel’s standpoint. And for the file, I’ve never archaic a baseball cap…

Digital Foundry: Clearly, going in the dedicated graphics enviornment is a surely attention-grabbing pattern for Intel. And it has been a truly very prolonged time in pattern, you may per chance presumably presumably even hold made no secret of your transfer right here, nevertheless what’s the final approach? Why are you coming into into the dedicated graphics place?
Lisa Pearce: For folk that scrutinize at it, it is an distinguished market. A mode of us hold been working in constructed-in graphics for a truly very prolonged time. Intel’s been in the graphics enterprise for two a protracted time, doing lower vitality, constrained develop component solutions – and the market’s hungry, I deem, for more alternatives in discrete graphics. So, we’re expansive enraged to enter it. It is for stride one which has mammoth aspirations with Xe, it is a scalable structure, not aesthetic for client, nevertheless also datacentre. It is some distance a surely attention-grabbing time, and I deem the enterprise is taking a glimpse forward to one other player there.
Digital Foundry: Completely. There used to be a convergence in phrases of the wants of the markets, proper? Clearly, Nvidia made a colossal impact in phrases of AI, ray tracing and all of this can converge with the gaming market – and it is massive to scrutinize that Intel is joining the fray as neatly. So we have had the Alchemist GPU published. And I’m going to place a matter to the do a matter to that you simply don’t settle on me to as – nevertheless where execute you inquire of it to land in phrases of the final market? What is this GPU going to execute for gamers? Which is to assert, that is my do a matter to which would not enjoy the observe ‘performance’ nevertheless is set performance!
Tom Petersen: Neatly, I might divulge clearly, Richard, we’re not going to talk about performance, so I cannot without extend acknowledge your do a matter to. But I will divulge that as you trip by what is Alchemist, it is a fleshy-featured gaming GPU first, proper? There may per chance presumably also be no do a matter to on your mind. And it is not an entry level GPU, it is for stride a competitive GPU. It is bought the final aspects which shall be wished for subsequent generation gaming. So, with out talking about performance, I’m horny focused on it.
Digital Foundry: Noteworthy. And it looks similar to you may per chance presumably presumably neatly be going to be first to the market with TSMC 6nm – attention-grabbing more than just a few there. Can you absolutely quantify the advantages that this direction of may per chance presumably presumably also give you over what’s already out in the marketplace and what you’re going to be going up in opposition to in Q1 2022?
Tom Petersen: Neatly, all any other time, that is getting a little bit too shut to performance. But clearly, being in the following generation direction of prior to other chips offers us an advantage. And there’s loads of consultants out there that can give more or less expertise roadmap projections, aesthetic not this one!
Intel’s XeSS machine discovering out-essentially essentially based mostly expansive-sampling expertise is taking a glimpse very promising certainly, judged by this early demo.
Digital Foundry: Taking a glimpse on the structure, we can explore there’s a focal level on rasterisation, clearly, nevertheless ray tracing and machine discovering out are front and centre, which is a more or less numerous approach than we saw with AMD and RDNA 2. And it is more similar to what we explore from Nvidia, focusing on machine discovering out and dedicated ray tracing cores, accelerating things enjoy ray traversal, shall we embrace. Intel’s going with that more or less ability, how come?
Tom Petersen: Neatly, to me, it is aesthetic the manner that expertise is evolving naturally. For folk that deem about AI as being utilized literally to each and each vertical utility on this planet, clearly, it will hold a distinguished impact on gaming. You might presumably presumably presumably also very neatly get better results than classic results by fusing AI-vogue compute to mature rendering. And I deem we’re aesthetic firstly of that expertise. At the present time, it is basically working on post rendered pixels. But clearly, I point out, that will not be the right place that AI goes to change gaming. So, I deem that is aesthetic a natural evolution.
And all any other time, while you deem about ray tracing, it delivers an even bigger consequence than mature rendering strategies. It would not work in every single place the place and clearly, there’s a performance trade-off. But it is aesthetic a large formula to make stronger the lifetime of gamers. So, I deem that these traits are going to continue to streak. And I deem it is amazing that there’s some alignment surely, attributable to that alignment between hardware vendors enjoy Intel and Nvidia and even AMD… that alignment permits the ISVs to scrutinize a steady platform of aspects. And that grows the final marketplace for games and that is the explanation surely what is correct for each person.
Digital Foundry: Objective from an architectural standpoint, I’m odd. Why rely on dedicated hardware, shall we embrace, for the ray tracing unit, in want to repurposing recent items that the GPU may per chance presumably presumably also honest hold already bought, and counting on aesthetic frequent compute, shall we embrace?
Tom Petersen: The mammoth cause there’s attributable to the nature of what’s going down while you may per chance presumably presumably neatly be doing ray traversal may per chance be very numerous. The algorithms are very numerous from a mature multi-pixel per chunk, , a pair of things in parallel. So deem of it as you may per chance presumably presumably neatly be in search of to acquire where these rays are intersecting triangles. It is some distance a branching vogue goal, and you aesthetic want a pair of numerous form of things. So that is surely algorithmic, the necessity may per chance presumably presumably be, ‘hi there, let’s streak all the pieces on shaders’ nevertheless in fact that is inefficient – even supposing I execute know that Nvidia did beget a version of that on hand for his or her older GPUs. And you keep in mind the performance disagreement between the dedicated hardware and the shader? It is dramatic. And it is miles attributable to the algorithm may per chance be very, very numerous.
Strive Intel’s fleshy Structure Day presentation whereas you may per chance presumably presumably neatly be technically inclined. The Alchemist stuff is big, nevertheless the Alder Lake CPU shall be taking a glimpse expansive.
Digital Foundry: A do a matter to on overall approach: you may per chance presumably presumably even hold confirmed one chip assemble, even supposing there used to be a hump with two chips. I’m assuming the idea goes to be that you simply’re going to hold a stack, proper? You can hold numerous parts, there may per chance presumably presumably also honest not be aesthetic one GPU coming up. Does the DG1 silicon aloof hold a role to play, or used to be that just about about enjoy a take a look at streak as such?
Lisa Pearce: Yeah, DG1 used to be our first step to run and work by quite loads of the assorted disorders and in search of to make certain that we prepped our stack used to be the first entry there, getting the driver tuned and prepared. So, DG1 used to be very major for us. But surely, Alchemist is the begin of aesthetic massive graphics performance GPUs. And there will doubtless be many following, which is the cause we shared some of those code names. It is for stride a multi-three hundred and sixty five days ability.
Digital Foundry: Let’s transfer on to something that is surely aesthetic as major to the project because the silicon, which is the tool stack. This is something where it looks enjoy it has been enjoy an ongoing ability. over a protracted time, I convey I first began to connect shut glimpse of Intel graphics more without extend with Ice Lake [10th generation Core]. And clearly, you may per chance presumably presumably even hold come on leaps and bounds since then. But what’s the approach in growing the tool stack? The place execute you absolutely want to be while you terminate up launching in Q1 2022. The place are you now and what are the fundamental accomplishments this day?
Lisa Pearce: Neatly, , we have been making ready for Xe HPG for a whereas. And a mammoth section of that is the driver stack having an structure that might also be scalable from constructed-in graphics with LP to HPG. And at the same time as you talked about one of the vital opposite architectures with HPC, as neatly. And so, it is major in the driver assemble, and it started final three hundred and sixty five days. Last three hundred and sixty five days at Structure Day, we talked about Monza, it used to be a mammoth change to our 3D driver stack to put collectively for that scaling. So that is the first major, then after that, in search of to hold the maturity in how we tune for numerous segments, numerous performance aspects and surely squeeze out every component of each and each outlandish structure product level.
So, inner the driver, we have had four major efforts going on, especially this three hundred and sixty five days making ready for this start. You appreciate, the first three are more frequent than that is particular to HPG particularly So, in search of to hold local memory optimisations, how neatly execute we use it? What’s our memory footprint? Are we placing the right kind things in local memory for each and each title? then the game load time performance… the burden time there used to be about 25 percent average good purchase this three hundred and sixty five days. Some are great heavier. The work is continuing. So, we have loads of work to execute there continuing into Q1 for start. Third used to be CPU utilisation, CPU stride titles, , I talked about on average, we more or less acknowledged things conservatively and 18 percent on average, [but] some titles [have] 80 percent good purchase. So that used to be surely the maturity of the Monza stack that we rolled out and in search of to squeeze the performance from that. After which the final one, clearly, how neatly does the driver feed the HPG, the larger structure. And so all of these are continuing. It is some distance a relentless look and tuning as recent games, recent workloads, especially on DX11/DX12. And you may per chance presumably presumably also explore that continue by Q1 for the start.

Digital Foundry: Okay, attributable to perception used to be that when we moved into the generation of the low-level APIs, the steady driver optimisation from the seller side would more or less attach shut a backseat to what’s going down with the developer. But that hasn’t took place proper?
Tom Petersen: No, it would not work that manner. I point out, the low level APIs hold given device more freedom to ISVs and they’ve created loads of surely cool applied sciences. But on the terminate of the day, a heavy attach shut is aloof required by the driver, the compiler alone is aesthetic a distinguished contributor to overall frame performances. And that goes to continue to be something that we are going to work on, clearly.
Digital Foundry: No longer aesthetic taking a glimpse on the most up-to-date titles and the most up-to-date APIs, does Intel hold any plans to elongate its performance and compatibility with legacy titles in the early DX11 to pre-DX11 generation, perchance?
Lisa Pearce: A mode of [driver optimisation] is in accordance with reputation, bigger than something, so we strive and make certain that that top titles folks are the usage of, those are the highest priority, clearly… some heavy DX11 nevertheless also DX9 titles. Additionally, in accordance with geographies, it is a numerous make-up of one of the most popular titles and APIs which shall be mature – so it is miles frequent. But clearly, the priority tends to tumble heaviest with one of the vital newer contemporary APIs, nevertheless we aloof execute hold even DX9 optimisations going on.
Tom Petersen: There is a whole class of things that you simply may per chance presumably presumably also execute to applications. Mediate of it as enjoy outdoor the utility, things that you simply may per chance presumably presumably also execute enjoy, ‘Howdy, you made the compiler faster, you may per chance presumably presumably also beget the driver faster.’ But what else can you execute? There are some surely cool things that you simply may per chance presumably presumably also furthermore be doing graphically, even treating the game as form of a unlit box. And I deem of all of that stuff as implicit. It is things which shall be going down with out recreation developer integration. But there’s device more stuff that you simply may per chance presumably presumably also execute while you start talking about recreation integration. So I surely feel enjoy Intel is at that place where we’re on both side, we have some things that we’re doing implicit, and loads of things which shall be utter.
Digital Foundry: Okay. In phrases of implicit driver functions, shall we embrace, does Intel thought to present more driver aspects when its HPG line does not without extend come out? Things enjoy half refresh charge v-sync, controllable MSAA, VRS over-shading, shall we embrace, attributable to I do know Alchemist does reduction hardware VRS and it will use over-shading for VR titles. Are there any form of very particular attention-grabbing things that we should always inquire of the HPG start?
Tom Petersen: There are many attention-grabbing aspects. I deem of it because the goodness beyond aesthetic being a large graphics driver, proper? It’s good to always be a large performance driver, and competitive on a perf per watt and in level of fact perf per transistor, you may per chance presumably presumably must hold all that. But you then also should always be pushing forward on the aspects beyond the basic graphic driver and you’re going to hear more about that as we acquire closer to HPG start. So I divulge stride, I’m horny assured.

Digital Foundry: Okay, so I want to transfer on to XeSS. We hold bought a demo, exhibiting it in motion. It is vastly thrilling, attributable to, we have been massive advocates of machine discovering out and the applications of machine discovering out. And it is absolutely amazing to scrutinize a upright competitor to DLSS coming into the market that may per chance presumably presumably presumably streak across more hardware, which I deem is key to its attach shut-up. So, the first component I want to place a matter to you is what used to be the drive to attain a image reconstruction approach in frequent from the Intel standpoint and why beget it pushed by machine discovering out processes?
Tom Petersen: Neatly, I might divulge there’s a continuum of performance and quality. For folk that deem about it, you render at low res and you’re going to also acquire excessive frame-charge, or whereas you render at excessive res, you have a tendency to acquire low frame-charge. And the do a matter to is, execute we execute higher than that? And the acknowledge appears to be like to be, yeah, whereas you start focused on unique systems to re-use recordsdata from prior frames, or from prior histories of games, you may per chance presumably presumably also attach pack up all that other recordsdata and use it to reconstruct an even bigger frame – and that is the explanation surely what’s going down with all of these AI essentially essentially based mostly, expansive-rendering or expansive-sampling strategies.
And on the terminate of the day, it is laborious work – it is don’t acquire me unsuitable – it is rocket science, and we have one of the vital perfect AI folks on this planet working on it. However the outcomes relate for themselves, you may per chance presumably presumably also very neatly acquire an even bigger consequence by both interpolating, or integrating recordsdata across a pair of frames. After which along side on to that recordsdata that might also be trained right into a neural community from taking a glimpse at millions or tons of of millions of frames from other games. It is surely aesthetic a spectacular expertise.
Digital Foundry: So it appears to be just like the manner you may per chance presumably presumably neatly be describing it there that there is a expansive coaching direction of in the background, presumably in accordance with extremely expansive-sampled pictures of sure games. After which the inference essentially essentially based mostly upon the weights generated from which shall be carried out in steady time on the GPU.
Tom Petersen: Yeah, clearly. And we have, clearly, a pair of flavours of that inference. However the cool section is that they are generic in the sense that they aren’t trained on a explicit title. The inference works across a pair of games, attributable to on the terminate of the day, they’re all very, very the same. And I deem of it as, it is almost the very best of the sphere where you may per chance presumably presumably also more or less divulge, attach shut this engine, educate it on a bunch of recordsdata that is from numerous games and then use that across a pair of numerous titles to acquire massive results.
Digital Foundry: Okay, talking referring to the assorted inferences and the paths you talked about there, your presentation specifically talked about the XMX route along with the DP4A route. Might per chance presumably per chance you doubtless run into more component about which of them are particular to the Intel structure and which of them are not, along with, presumably variations in performance and perceptual image quality that every and each may per chance presumably presumably also need on Intel structure?
This is what Intel has to study and doubtless exceed – this video showcases the engaging RT in Lego Builder’s Lunge, then goes into depth on Nvidia’s most modern enhancements with DLSS 2.2.
Tom Petersen: So, in fact that folk confuse all these rendering strategies, and post render strategies, and they more or less mix all of them collectively into ‘imagery gets higher’. But there are some surely numerous things going on. In frequent, there’s something that I deem of as upscaling or normally folks name it ‘expansive resolution’. And what you may per chance presumably presumably neatly be doing there’s you may per chance presumably presumably neatly be taking a low resolution image from a single frame, and you’re going to neatly be more or less blowing it up the usage of a pair of numerous strategies. And that may per chance presumably presumably also very neatly be a surely excessive performance approach that gives you an good sufficient lead to many conditions, nevertheless it would not hold the final recordsdata on hand to it, it would not learn about prior rendered frames and would not learn about motion vectors. And it would not surely know referring to the history of all frames that ever been generated.
So whereas you overview that upscaling approach, or upsampling – I deem upscaling is an even bigger observe – whereas you overview that expertise to what’s going down with something enjoy XeSS, in XeSS, we’re taking a pair of frames of the game. And we’re taking a glimpse at motion vectors and we’re also taking a glimpse at prior rendered frames which hold been trained right into a community. So successfully, we’re taking a glimpse at device more recordsdata to generate that recent frame, that has an even bigger characteristic than mature upscaling.
Now, while you deem about how execute you streak that XeSS algorithm? The preliminary ones we have talked about are the XMX engines, which shall be systolic that is kind of the mature manner of doing rapid inference on a GPU. And the opposite manner is DP4A, which is one other more or less more efficient develop that might also be more broadly adopted across a pair of numerous architectures. So I deem of it as, on hardware platforms from Intel that reduction the core engine, we inquire of to attain XeSS on hand on that instrument. So that is, that is horny cool, proper? You more or less divulge, we have a pair of backends that every one fling in below a frequent API. And that’s, to me, the very best component is that ISVs strive and acquire these frequent APIs. So that they’ll execute one integration.
After which below that integration, you may per chance presumably presumably in actual fact hold a pair of implementations of the engine with out ISVs having to re-integrate and re-overview on every occasion so our expectation is that that is precisely what XeSS is – it has a standardised API that may per chance presumably presumably even work across a pair of vendors. And so, section of the fundamental process of XeSS is to be begin, let’s acquire these API’s out there. And let’s let other folks implement below these so that we can beget the lifetime of ISVs a little bit more uncomplicated. And over time, the hope is that this more or less stuff will clearly, transfer up higher into scandalous enterprise, standardized APIs, nevertheless all that stuff takes time. So what we’re more or less thinking is, hi there, let’s acquire our first version out there, beget it superior, then submit it, beget the APIs begin, and then over time, it gets standardised.

Digital Foundry: So as a component of that, you role your hold SDK – your hold API – out there that will not without extend trickle down, or trickle upwards into something more broadly standardized.. is the first iteration surely the usage of Microsoft DirectML at all as section of it?
Tom Petersen: No. Now, there’s a correct do a matter to about that: why not? In fact we have our hold inner programming language that we’re the usage of for the excessive performance kernels which shall be section of the implementation of XeSS. And all that stuff proper now may per chance presumably presumably be extremely Intel ‘in kitchen’ more or less expansive optimised fused kernels, enjoy horny, , almost enjoy a dude.. coding in assembly from merit in the day. I will be mindful enjoy Richard with a diminutive little ball cap doing that. We hold got enjoy a whole room of those folks making XeSS aesthetic supreme. So that is where we are this day. But over time as divulge, Microsoft’s APIs for shaders lengthen, presumably this whole component can aesthetic become shader essentially essentially based mostly, nevertheless it is not. [Right now] mature shaders are not optimised for the XMX vogue structure.
Digital Foundry: Yeah, aesthetic for the file, I checked out [of assembly coding] with 6502, that is how previous I’m! I convey a more nuts and bolts do a matter to out of your demo: you were exhibiting 1080p scaled via XeSS to 4K. Will you be supporting numerous inner resolutions?
Tom Petersen: Yeah, I deem you’re going to explore XeSS will reduction a pair of numerous configurations. There is enjoy a high quality mode or performance mode, and numerous enter resolutions to numerous output resolutions. I’m undecided what that scandalous matrix goes to scrutinize enjoy proper now. But there’s not any need for this to be aesthetic ‘one in, one out’.
Digital Foundry: And on the SDK side of things, I point out, all of these aspects are living and die by surely getting utilized in titles, proper? So how begin is begin? Are we talking about source code on GitHub, or something more similar to what Nvidia did with the DLSS SDK?
Tom Petersen: So the manner to deem about it is that it is for stride in each person’s passion to hold begin ISV API’s. And what that device is, literally the identical API, each person integrates that and below it, you fling standard of numerous DLLs that implement the engines, on the final, which shall be enforcing the aspects. That’s going to connect shut a whereas, proper? So in the instant timeframe, what we are going to doubtless be doing, and I deem there’s aloof a little little bit of motion right here is to submit the APIs, submit the SDKs, and submit references and then successfully ISVs will know what they’re getting. And there’s surely nothing about that that feels awkward to me. over time, you’re going to enjoy to be device more begin, where there’s these APIs that folk can fling in below them. And that’s successfully the approach. Now, we are going to aloof very doubtless hold our hold inner engines that fling below these APIs. And over time, whether or not those are going to be begin or not, it is not sure.
Digital Foundry: Okay, so is there surely a form of limitation on which GPUs from other vendors will streak it? I point out, I’m assuming there has to be some more or less machine discovering out acceleration enthusiastic, proper?
Tom Petersen: That’s, that is surely a do a matter to for other vendors, proper? You might presumably presumably presumably also honest hold got considered these machine discovering out vogue applications streak on GPUs with none, proper? There will not be any cause it has to hold a explicit hardware. It is aesthetic a performance, quality more or less complexity trade off.
Digital Foundry: Here’s a challenging belief that I had for the length of the Structure Day, which is that in actual fact, you may per chance presumably presumably hold machine discovering out silicon not aesthetic in the GPU, nevertheless also in the CPU. Shall we embrace, I hold an older GeForce or Radeon card, and I want to tap into XeSS. Can I execute that via the CPU?
Tom Petersen: Neatly, that there’s an constructed-in GPU on most of our CPUs. And so, the do a matter to is, what wouldn’t it scrutinize enjoy? And I’m stride, you may per chance presumably presumably neatly be attentive to enjoy how hybrid works for many notebooks where there’s a discrete GPU render, and then there’s a reproduction to an constructed-in GPU, that this day does nothing as opposed to act as a notify controller surely. But now that we have applied sciences which shall be surely cool, may per chance presumably presumably we execute something attention-grabbing on the GPU? I deem that whole place, we known as it Deep Link. And what happens in phrases of Deep Link proper now, we’re aloof discovering out so great right here. And there are so great of alternatives. At the present time, it is aesthetic Intel products working collectively, nevertheless you may per chance presumably presumably also deem about Deep Link as aesthetic enjoy, what execute we execute in a two GPU ambiance or a CPU/GPU ambiance that is higher than in any other case? So, I beget not want to acknowledge to that do a matter to without extend, nevertheless let’s aesthetic divulge there’s tons of assorted in that place.

Digital Foundry: From an Intel level of scrutinize, whereas you may per chance presumably presumably neatly be ready to take care of machine discovering out silicon, does it fundamentally topic if it is on the CPU or GPU? That’s more or less the do a matter to I have been pondering.
Tom Petersen: It is the performance, , it is miles the perf per watt… is the compute in the right kind place to hold an label on the pixels which shall be transferring by the pipeline. There will not be any religion about it. It is aesthetic enjoy, where does the science lead us to? Will we have a goal that goes ship advantages to customers? And if we execute, yeah, we are going to execute it doubtless. I point out, there will doubtless be no hesitation if we acquire a large expertise that makes our CPUs ship an even bigger expertise than somebody else’s.
Digital Foundry: Objective one other rapid do a matter to right here referring to the ray tracing setup on this GPU structure. It does hold a dedicated ray tracing block that accelerates a pair of things. It looks enjoy it is outdoor the fundamental core scheme so can it streak on the identical time as with the customary vector engines or XMX engines to further lengthen utilisation, saturation or aesthetic GPU parallelism working one of the most on the identical time.
Tom Petersen: Unfortunately, I beget not know the acknowledge to that. I deem stride, nevertheless I might not want to double take a look at on that. Okay, that is an elegant do a matter to, though. Stump the host!
Digital Foundry: A mode of wonderful applied sciences that were published and talked about on the Structure Day. And clearly, on the terminate, there used to be the moonshot, Ponte Vecchio. This shall be a truly numerous scheme to what we’re talking about in phrases of mainstream user graphics. Nonetheless, tips wise, you were exhibiting scalability on a multi-chip level, proper? You were bringing a pair of GPUs collectively. And from the looks of it in phrases of how they’re linked, they appear to act as one coherent whole. Now, clearly, in the gaming place, the idea that of bringing collectively a pair of GPUs collectively and to streak performance died with SLI, it did not surely scale to contemporary architectures, to temporal applications, specifically. My do a matter to right here is correct taking a glimpse to the future, may per chance presumably presumably Ponte Vecchio-vogue expertise scale down to the user level?
Tom Petersen: Neatly, all any other time, I beget not want to talk about unreleased products, nevertheless let’s merit as a lot as Ponte Vecchio. The target of Ponte Vecchio is compute, proper? And compute scales very with out teach, very naturally. And having a pair of compute die across a gigantic workload is aesthetic a surely clear-prick scaling direction of. There will not be a heavy tool mapping component that has to happen. It is extremely great the manner the problem is defined with expansive laptop loads. That’s very numerous on user. I convey I’m going to present you my sense from the outdoor about what’s made SLI sophisticated – it is miles the multi frame nature of SLI, where you may per chance presumably presumably neatly be more or less in search of to assert, AFR [alternate frame rendering] is the expertise they use and the basis is they render one frame in each and each GPU that is temporarily separated, and then they’re aesthetic going to notify them in [sequence]. That approach breaks down with contemporary titles, attributable to of post-processing and frame-to-frame scandalous dialog.
So, , to execute it on user, we would wish a brand recent expertise, a brand recent manner of partitioning work across a pair of tiles. And the extent to which there’s excessive bandwidth dialog across that tile, you may per chance presumably presumably also more or less ignore the truth that they are a pair of tiles. Love if they had loads of bandwidth between tiles, they aesthetic scrutinize enjoy a mammoth piece of silicon, and there’s not any tool-visible behaviour. Now, there’s not going to be loads of bandwidth, so there’s going to be some more or less work to execute that scaling across tiles. But I deem that is the model. I point out, whereas you aesthetic scrutinize at how silicon works and you scrutinize at how yield works, having a pair of smaller die over time may per chance presumably presumably neatly be a surely correct thought – and that may per chance presumably presumably should always be made to work by some ability. It is not going to be something enjoy SLI. SLI is a expertise that worked massive with the DX9 and DX11. It is some distance also something numerous, I deem.

Digital Foundry: This do a matter to is a little more global and it is in actual fact about relationships with developers, attributable to right here’s aesthetic as major to getting correct performance because the silicon and the driver… you absolutely hold be there with the developer to lend a hand them to optimise for particular architectures. What is Intel’s imaginative and prescient there? How are you deploying that form of thought?
Lisa Pearce: We hold had a deep engagement with the gaming ISVs for a truly very prolonged time across Intel, proper. But now, it is at a level of an distinguished deeper engineering engagement. And it has been constructing for the final two years, we realize it is serious table stakes for achievement and excessive performance user graphics. So, it has been constructing stronger and stronger [relationships], giving more succesful tools, more succesful SDKs and bringing them along to lend a hand make certain that that we have the very best imaginable expertise for gaming on Alchemist. And in the following couple of years, we would inquire of, , not without extend, some distance bigger than day zero driver alignment: up front tuning, upfront engagement, presumably some outlandish optimisations that we can run and drive in even sooner than it is in the final stage for start. So, we scrutinize those relationships as absolutely serious to the manner forward for discrete graphics.
Digital Foundry: There is also been a drive to elongate performance adjacent to gaming – not particular to gaming. As an illustration, streaming. How are things going there and what are the plans for the future?
Lisa Pearce: You appreciate, in streaming, right here’s one of the conditions where we surely explore Deep Link as a challenging expertise for us to continue to make stronger on. It is consistently massive when we have constructed-in and discrete graphics on the scheme. Buy and streaming is one of them – our encoders hold been a steady level for a whereas. How execute we make certain that we leverage the steadiness of excessive performance, what quality ranges we need… there will doubtless be loads of sure solutions we want to elevate there. And we are going to explore more about that with the Alchemist start.
Digital Foundry: I hold a little bonus do a matter to referring to the disagreement between the HPG and HPC setup, I seen that the EU is awfully quite a bit wider, enjoy twice as huge in the HPC enviornment. What’s the assemble resolution for that and to not use that in the excessive performance graphics role-up?
Tom Petersen: Neatly, it is all referring to the section that they are focused on, clearly. There is some parallelism that is more prevalent in the workloads at numerous segments. And I might attribute quite loads of the architectural disagreement to the workloads that the architectures tune for.
Digital Foundry: For my one closing do a matter to… returning to machine discovering out. Most frequently, it is miles the recent frontier, proper? This is where the prospects are never-ending. But, , what’s the following probability? Clearly, expansive-sampling is the mammoth one for the time being. Elevate out you may per chance presumably presumably hold any thoughts on where things are going to run subsequent in the gaming enviornment?
Tom Petersen: I hold a million thoughts! But I beget not want to talk about them Richard! But I will say you a pair of things, attributable to, , it is aesthetic clear-prick to me proper now. We’re working on post rendered pixels, and post render pixels, [so] you may per chance presumably presumably even hold left quite loads of the tips already earlier in the pipeline. And so the do a matter to is, is this thought of fusing more recordsdata from deeper merit or presumably even begin taking to scrutinize at physics engines… and what referring to the final opposite engines which shall be feeding into the render, enjoy projection and geometry expansion? So, there are aesthetic many, many, many algorithms which shall be working which shall be prior to pixels and all of those are candidates for feeding into some more or less generative algorithm, which is absolutely what AI is all about. AI does two things. One is extrapolation where it says ‘there’s recordsdata right here, I’m aesthetic going to transfer it forward in some more or less reasonable manner’. But it also does hallucination, where you more or less divulge, I’ve considered things in the previous which shall be enjoy this. So would not or not it is massive if there used to be a tree right here? You appreciate, right here’s what AI does and all of that stuff is supreme for games. And there are varied, many numerous applications…